 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory-oriented Image Selection and Placement
Paper and Code
Sep 02, 2019
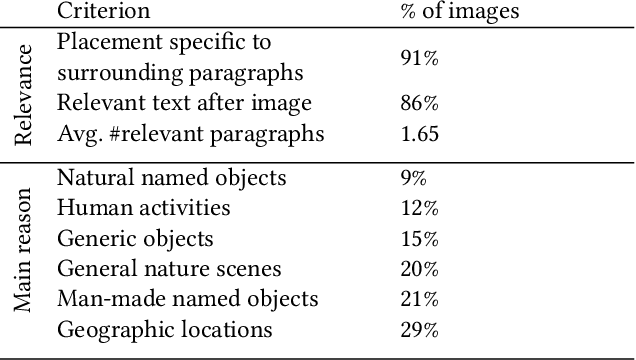

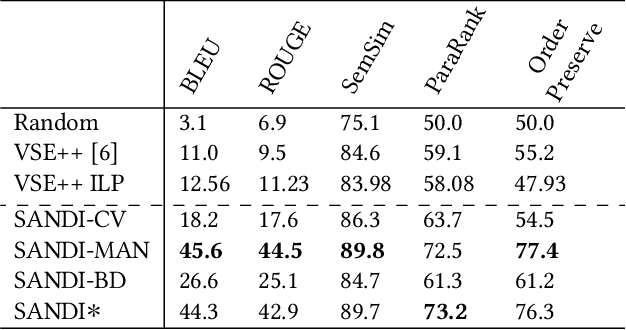
Multimodal contents have become commonplace on the Internet today, manifested as news articles, social media posts, and personal or business blog posts. Among the various kinds of media (images, videos, graphics, icons, audio) used in such multimodal stories, images are the most popular. The selection of images from a collection - either author's personal photo album, or web repositories - and their meticulous placement within a text, builds a succinct multimodal commentary for digital consumption. In this paper we present a system that automates the process of selecting relevant images for a story and placing them at contextual paragraphs within the story for a multimodal narration. We leverage automatic object recognition, user-provided tags, and commonsense knowledge, and use an unsupervised combinatorial optimization to solve the selection and placement problems seamlessly as a single unit.