 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixelVAE++: Improved PixelVAE with Discrete Prior
Paper and Code
Aug 26, 2019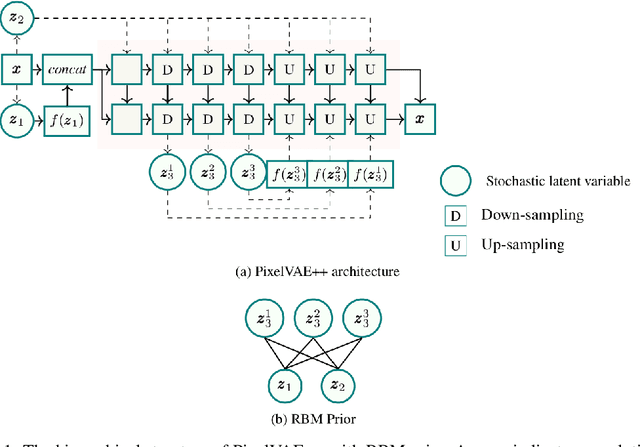
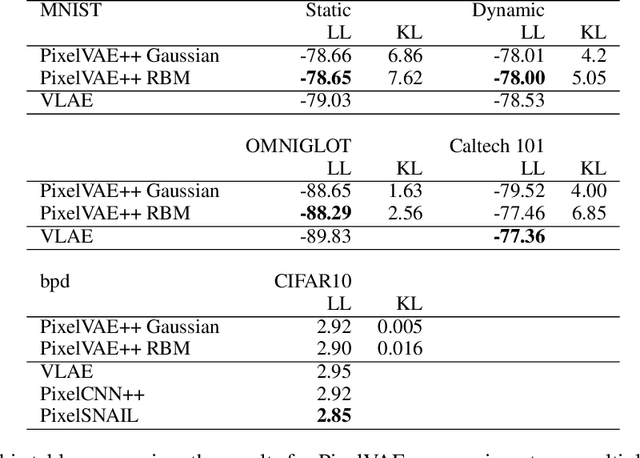


Constructing powerful generative models for natural images is a challenging task. PixelCNN models capture details and local information in images very well but have limited receptive field. Variational autoencoders with a factorial decoder can capture global information easily, but they often fail to reconstruct details faithfully. PixelVAE combines the best features of the two models and constructs a generative model that is able to learn local and global structures. Here we introduce PixelVAE++, a VAE with three types of latent variables and a PixelCNN++ for the decoder. We introduce a novel architecture that reuses a part of the decoder as an encoder. We achieve the state of the art performance on binary data sets such as MNIST and Omniglot and achieve the state of the art performance on CIFAR-10 among latent variable models while keeping the latent variables informative.