 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning with Autoencoders for Electronic Health Records: A Comparative Study
Paper and Code
Sep 20, 2019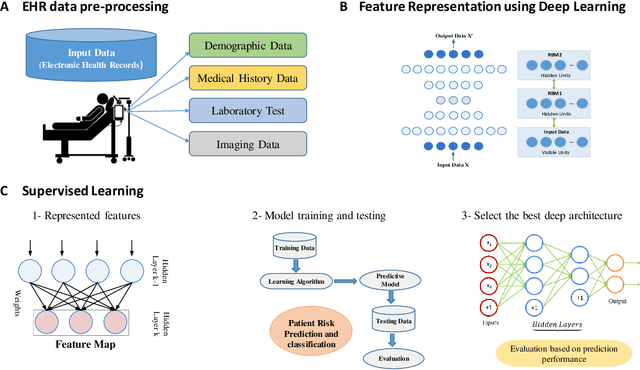
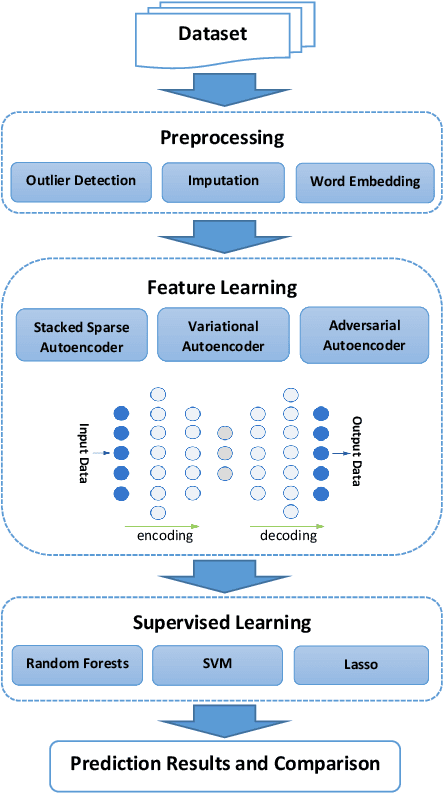
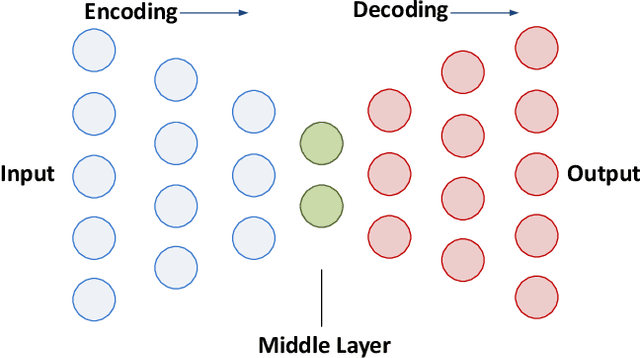
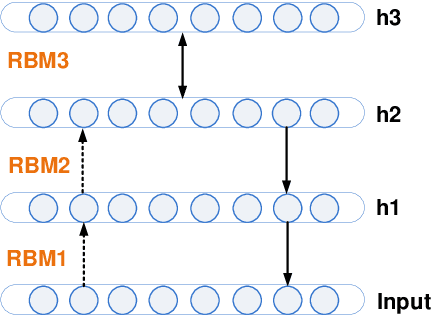
Increasing volume of Electronic Health Records (EHR) in recent years provides great opportunities for data scientists to collaborate on different aspects of healthcare research by applying advanced analytics to these EHR clinical data. A key requirement however is obtaining meaningful insights from high dimensional, sparse and complex clinical data. Data science approaches typically address this challenge by performing feature learning in order to build more reliable and informative feature representations from clinical data followed by supervised learning. In this paper, we propose a predictive modeling approach based on deep learning based feature representations and word embedding techniques. Our method uses different deep architectures (stacked sparse autoencoders, deep belief network, adversarial autoencoders and variational autoencoders) for feature representation in higher-level abstraction to obtain effective and robust features from EHRs, and then build prediction models on top of them. Our approach is particularly useful when the unlabeled data is abundant whereas labeled data is scarce. We investigate the performance of representation learning through a supervised learning approach. Our focus is to present a comparative study to evaluate the performance of different deep architectures through supervised learning and provide insights in the choice of deep feature representation techniques. Our experiments demonstrate that for small data sets, stacked sparse autoencoder demonstrates a superior generality performance in prediction due to sparsity regularization whereas variational autoencoders outperform the competing approaches for large data sets due to its capability of learning the representation distribution