 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIDGE: Byzantine-resilient Decentralized Gradient Descent
Paper and Code
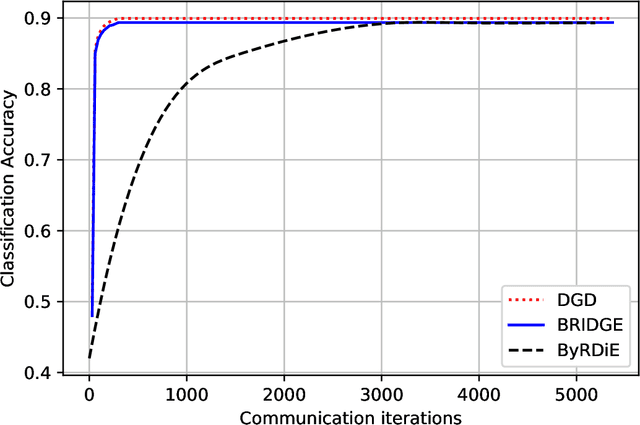
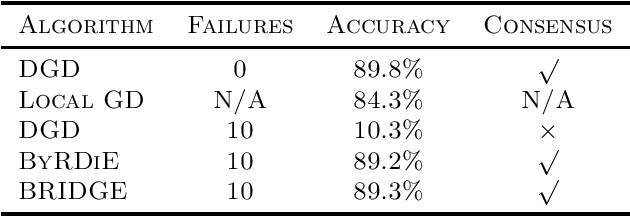
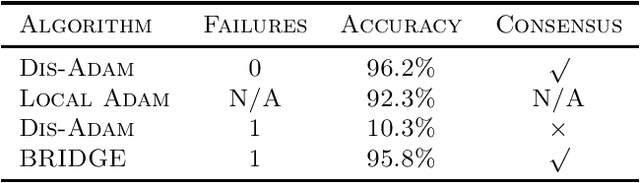
Decentralized optimization techniques are increasingly being used to learn machine learning models from data distributed over multiple locations without gathering the data at any one location. Unfortunately, methods that are designed for faultless networks typically fail in the presence of node failures. In particular, Byzantine failures---corresponding to the scenario in which faulty/compromised nodes are allowed to arbitrarily deviate from an agreed-upon protocol---are the hardest to safeguard against in decentralized settings. This paper introduces a Byzantine-resilient decentralized gradient descent (BRIDGE) method for decentralized learning that, when compared to existing works, is more efficient and scalable in higher-dimensional settings and that is deployable in networks having topologies that go beyond the star topology. The main contributions of this work include theoretical analysis of BRIDGE for strongly convex learning objectives and numerical experiments demonstrating the efficacy of BRIDGE for both convex and nonconvex learning tasks.