 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Growth in Medical Image Analysis Research
Paper and Code
Aug 21, 2019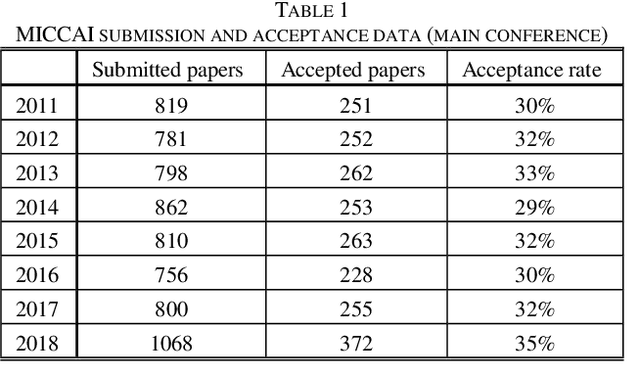
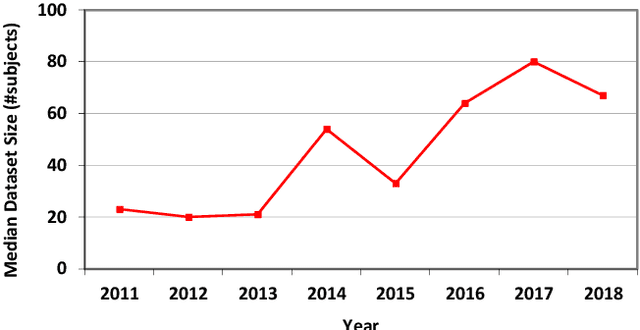
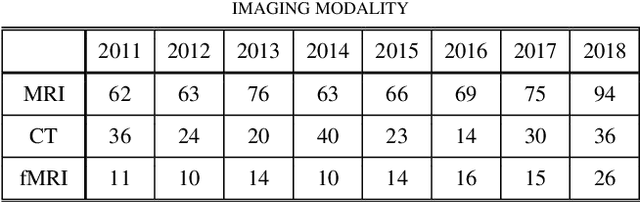
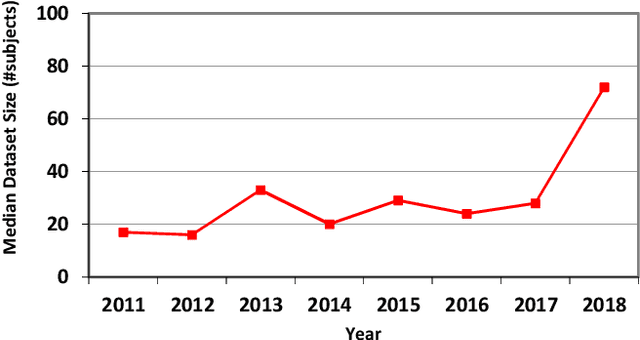
Medical image analysis studies usually require medical image datasets for training, testing and validation of algorithms. The need is underscored by the deep learning revolution and the dominance of machine learning in recent medical image analysis research. Nevertheless, due to ethical and legal constraints, commercial conflicts and the dependence on busy medical professionals, medical image analysis researchers have been described as "data starved". Due to the lack of objective criteria for sufficiency of dataset size, the research community implicitly sets ad-hoc standards by means of the peer review process. We hypothesize that peer review requires researchers to report the use of ever-increasing datasets as one condition for acceptance of their work to reputable publication venues. To test this hypothesis, we scanned the proceedings of the eminent MICCAI (Medical Image Computing and Computer-Assisted Intervention) conferences from 2011 to 2018. From a total of 2136 articles, we focused on 907 papers involving human datasets of MRI (Magnetic Resonance Imaging), CT (Computed Tomography) and fMRI (functional MRI) images. For each modality, for each of the years 2011-2018 we calculated the average, geometric mean and median number of human subjects used in that year's MICCAI articles. The results corroborate the dataset growth hypothesis. Specifically, the annual median dataset size in MICCAI articles has grown roughly 3-10 times from 2011 to 2018, depending on the imaging modality. Statistical analysis further supports the dataset growth hypothesis and reveals exponential growth of the geometric mean dataset size, with annual growth of about 21% for MRI, 24% for CT and 31% for fMRI. In slight analogy to Moore's law, the results can provide guidance about trends in the expectations of the medical image analysis community regarding dataset size.