 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Wrong with Hebrew NLP? And How to Make it Right
Paper and Code
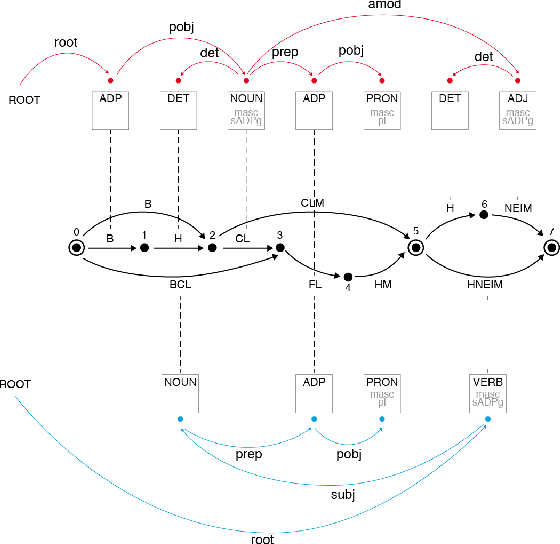
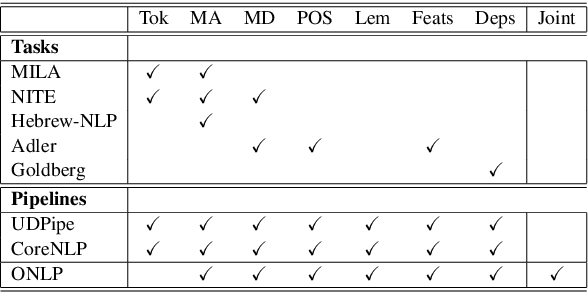
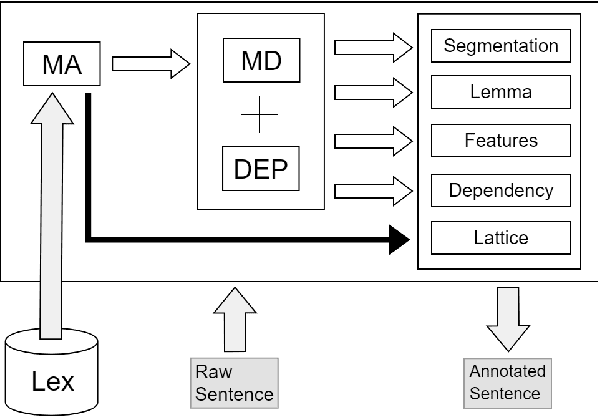
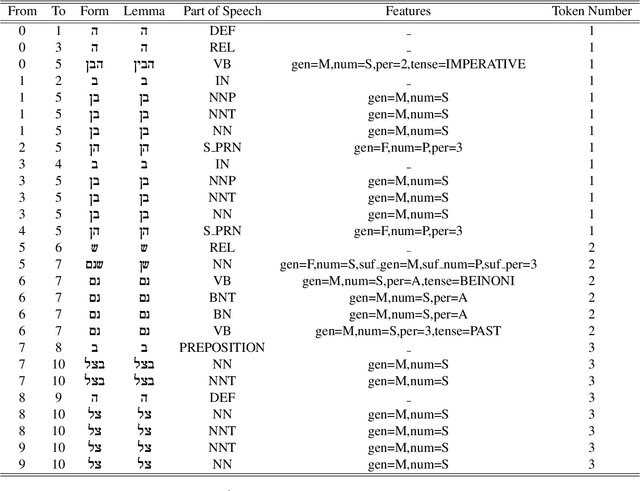
For languages with simple morphology, such as English, automatic annotation pipelines such as spaCy or Stanford's CoreNLP successfully serve projects in academia and the industry. For many morphologically-rich languages (MRLs), similar pipelines show sub-optimal performance that limits their applicability for text analysis in research and the industry.The sub-optimal performance is mainly due to errors in early morphological disambiguation decisions, which cannot be recovered later in the pipeline, yielding incoherent annotations on the whole. In this paper we describe the design and use of the Onlp suite, a joint morpho-syntactic parsing framework for processing Modern Hebrew texts. The joint inference over morphology and syntax substantially limits error propagation, and leads to high accuracy. Onlp provides rich and expressive output which already serves diverse academic and commercial needs. Its accompanying online demo further serves educational activities, introducing Hebrew NLP intricacies to researchers and non-researchers alike.