 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Deep Neural Networks Using Spectrum-Based Fault Localization
Paper and Code

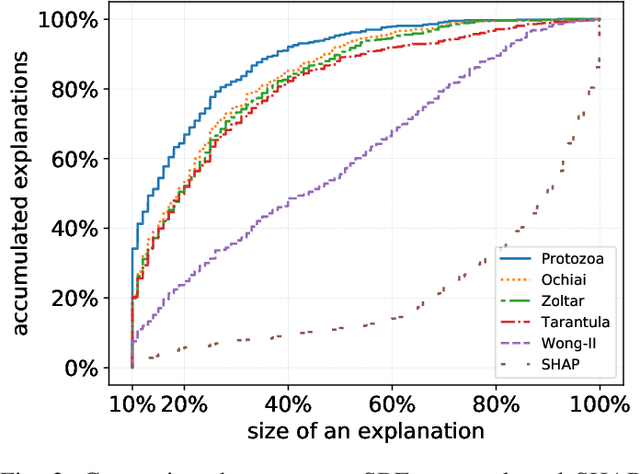

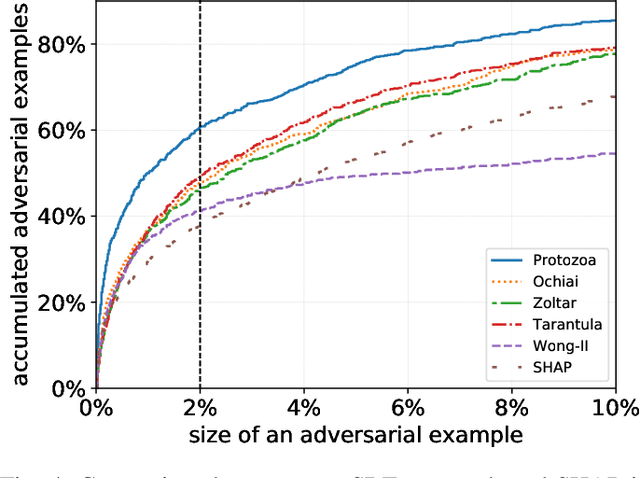
Deep neural networks (DNNs) increasingly replace traditionally developed software in a broad range of applications. However, in stark contrast to traditional software, the black-box nature of DNNs makes it impossible to understand their outputs, creating demand for "Explainable AI". Explanations of the outputs of the DNN are essential for the training process and are supporting evidence of the adequacy of the DNN. In this paper, we show that spectrum-based fault localization delivers good explanations of the outputs of DNNs. We present an algorithm and a tool PROTOZOA, which synthesizes a ranking of the parts of the inputs using several spectrum-based fault localization measures. We show that the highest-ranked parts provide explanations that are consistent with the standard definitions of explanations in the literature. Our experimental results on ImageNet show that the explanations we generate are useful visual indicators for the progress of the training of the DNN. We compare the results of PROTOZOA with SHAP and show that the explanations generated by PROTOZOA are on par or superior. We also generate adversarial examples using our explanations; the efficiency of this process can serve as a proxy metric for the quality of the explanations. Our measurements show that PROTOZOA's explanations yield a higher number of adversarial examples than those produced by SHAP.