 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Leisurely Look at Versions and Variants of the Cross Validation Estimator
Paper and Code
Jul 31, 2019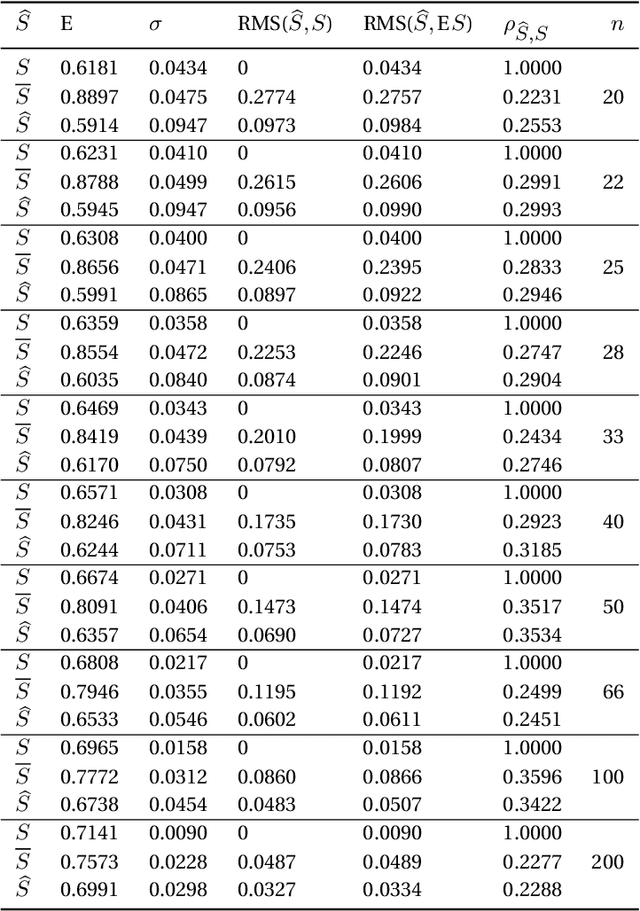

Many versions of cross-validation (CV) exist in the literature; and each version though has different variants. All are used interchangeably by many practitioners; yet, without explanation to the connection or difference among them. This article has three contributions. First, it starts by mathematical formalization of these different versions and variants that estimate the error rate and the Area Under the ROC Curve (AUC) of a classification rule, to show the connection and difference among them. Second, we prove some of their properties and prove that many variants are either redundant or "not smooth". Hence, we suggest to abandon all redundant versions and variants and only keep the leave-one-out, the $K$-fold, and the repeated $K$-fold. We show that the latter is the only among the three versions that is "smooth" and hence looks mathematically like estimating the mean performance of the classification rules. However, empirically, for the known phenomenon of "weak correlation", which we explain mathematically and experimentally, it estimates both conditional and mean performance almost with the same accuracy. Third, we conclude the article with suggesting two research points that may answer the remaining question of whether we can come up with a finalist among the three estimators: (1) a comparative study, that is much more comprehensive than those available in literature and conclude no overall winner, is needed to consider a wide range of distributions, datasets, and classifiers including complex ones obtained via the recent deep learning approach. (2) we sketch the path of deriving a rigorous method for estimating the variance of the only "smooth" version, repeated $K$-fold CV, rather than those ad-hoc methods available in the literature that ignore the covariance structure among the folds of CV.