 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Selection for training Semantic Segmentation CNNs with cross-dataset weak supervision
Paper and Code
Jul 16, 2019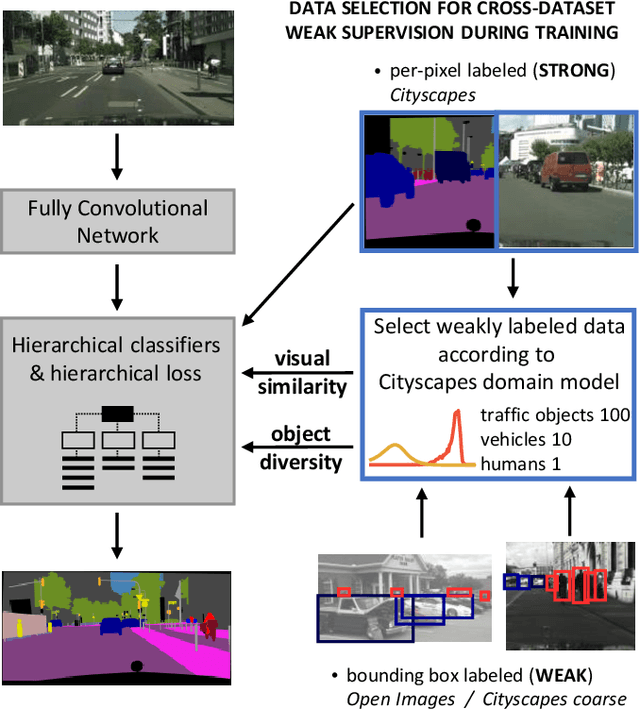


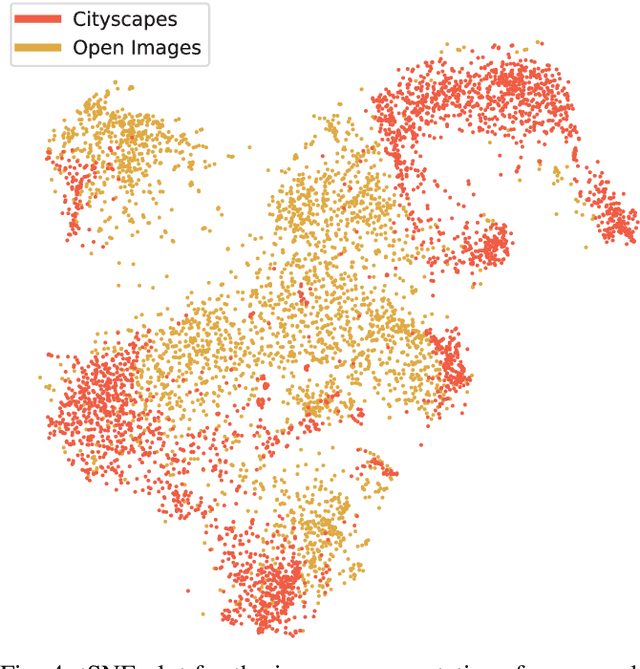
Training convolutional networks for semantic segmentation with strong (per-pixel) and weak (per-bounding-box) supervision requires a large amount of weakly labeled data. We propose two methods for selecting the most relevant data with weak supervision. The first method is designed for finding visually similar images without the need of labels and is based on modeling image representations with a Gaussian Mixture Model (GMM). As a byproduct of GMM modeling, we present useful insights on characterizing the data generating distribution. The second method aims at finding images with high object diversity and requires only the bounding box labels. Both methods are developed in the context of automated driving and experimentation is conducted on Cityscapes and Open Images datasets. We demonstrate performance gains by reducing the amount of employed weakly labeled images up to 100 times for Open Images and up to 20 times for Cityscapes.