 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicitly Conditioned Melody Generation: A Case Study with Interdependent RNNs
Paper and Code

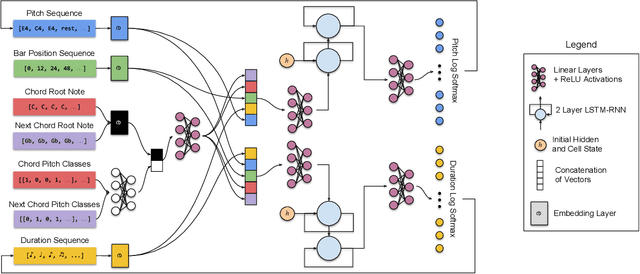
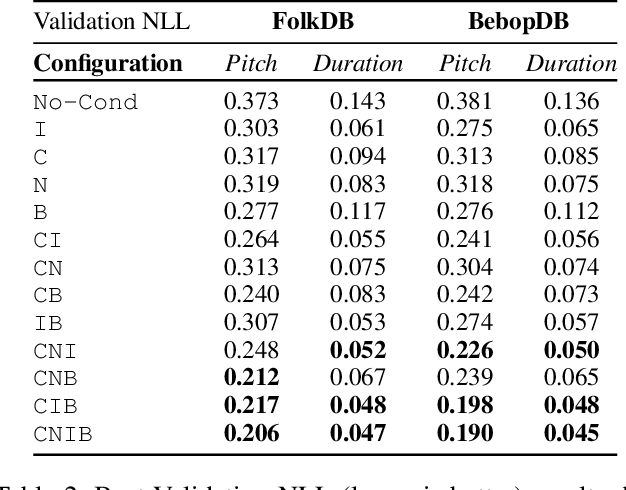
Deep generative models for symbolic music are typically designed to model temporal dependencies in music so as to predict the next musical event given previous events. In many cases, such models are expected to learn abstract concepts such as harmony, meter, and rhythm from raw musical data without any additional information. In this study, we investigate the effects of explicitly conditioning deep generative models with musically relevant information. Specifically, we study the effects of four different conditioning inputs on the performance of a recurrent monophonic melody generation model. Several combinations of these conditioning inputs are used to train different model variants which are then evaluated using three objective evaluation paradigms across two genres of music. The results indicate musically relevant conditioning significantly improves learning and performance, and reveal how this information affects learning of musical features related to pitch and rhythm. An informal subjective evaluation suggests a corresponding improvement in the aesthetic quality of generations.