 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaim Extraction in Biomedical Publications using Deep Discourse Model and Transfer Learning
Paper and Code

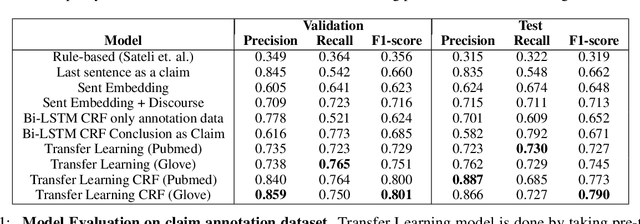
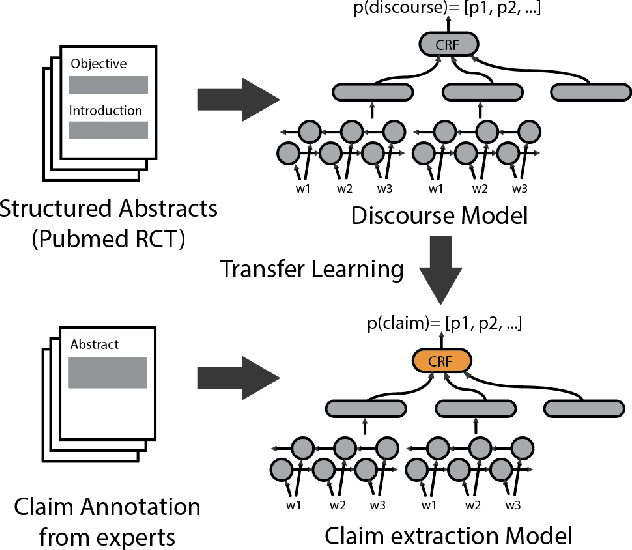
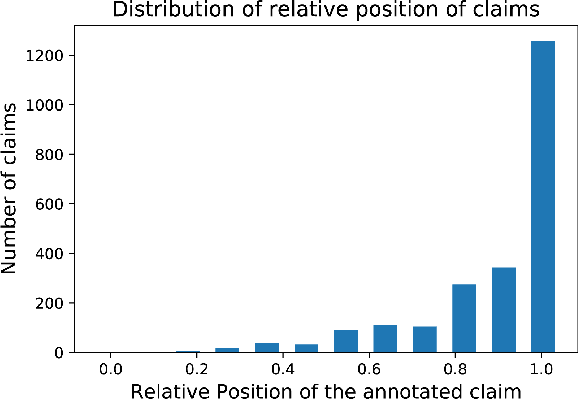
Claims are a fundamental unit of scientific discourse. The exponential growth in the number of scientific publications makes automatic claim extraction an important problem for researchers who are overwhelmed by this information overload. Such an automated claim extraction system is useful for both manual and programmatic exploration of scientific knowledge. In this paper, we introduce an online claim extraction system and a dataset of 1,500 scientific abstracts from the biomedical domain with expert annotations for each sentence indicating whether the sentence presents a scientific claim. We compare our proposed model with several baseline models including rule-based and deep learning techniques. Our transfer learning approach with a fine-tuning step allows us to bootstrap from a large discourse-annotated dataset (Pubmed-RCT) and obtains F1-score over 0.78 for claim detection while using a small annotated dataset of 750 papers. We show that using this pre-trained model based on the discourse prediction task improves F1-score by over 14 percent absolute points compared to a baseline model without discourse structure. We release a publicly accessible tool for discourse model, claim detection model, along with an annotation tool. We discuss further applications beyond Biomedical literature.