 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Spiky Corruption in Markov Decision Processes
Paper and Code
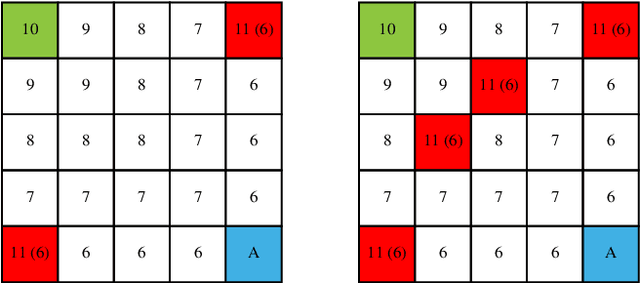

Current reinforcement learning methods fail if the reward function is imperfect, i.e. if the agent observes reward different from what it actually receives. We study this problem within the formalism of Corrupt Reward Markov Decision Processes (CRMDPs). We show that if the reward corruption in a CRMDP is sufficiently "spiky", the environment is solvable. We fully characterize the regret bound of a Spiky CRMDP, and introduce an algorithm that is able to detect its corrupt states. We show that this algorithm can be used to learn the optimal policy with any common reinforcement learning algorithm. Finally, we investigate our algorithm in a pair of simple gridworld environments, finding that our algorithm can detect the corrupt states and learn the optimal policy despite the corruption.