 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Models to Extract Treatment Plans from Clinical Notes Using Contents of Sections with Headings
Paper and Code
Jun 27, 2019
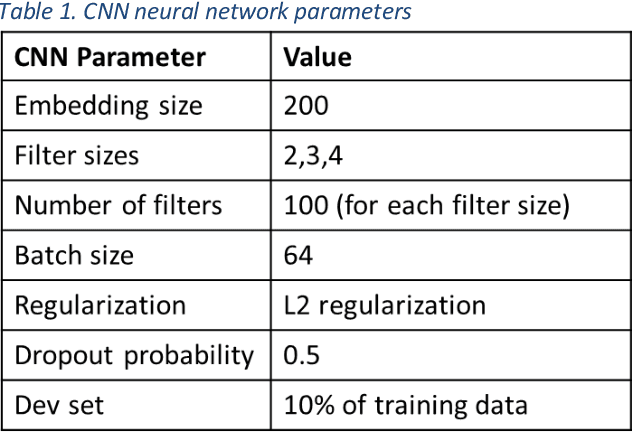
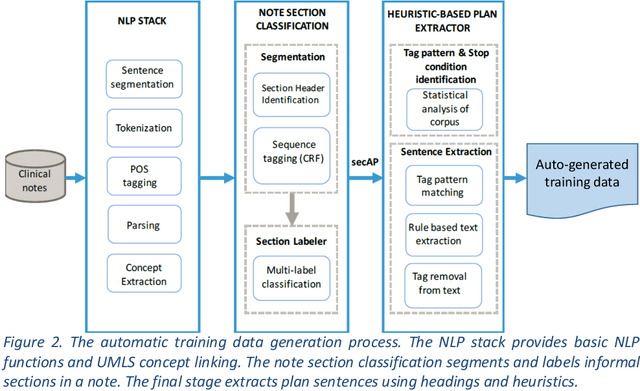
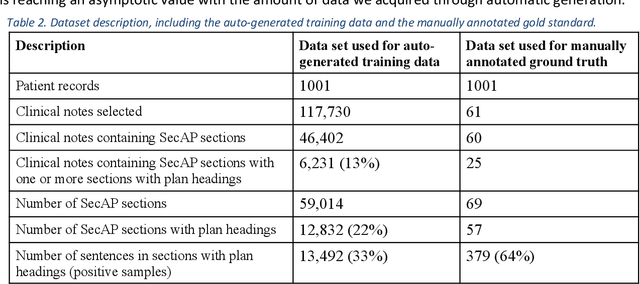
Objective: Using natural language processing (NLP) to find sentences that state treatment plans in a clinical note, would automate plan extraction and would further enable their use in tools that help providers and care managers. However, as in the most NLP tasks on clinical text, creating gold standard to train and test NLP models is tedious and expensive. Fortuitously, sometimes but not always clinical notes contain sections with a heading that identifies the section as a plan. Leveraging contents of such labeled sections as a noisy training data, we assessed accuracy of NLP models trained with the data. Methods: We used common variations of plan headings and rule-based heuristics to find plan sections with headings in clinical notes, and we extracted sentences from them and formed a noisy training data of plan sentences. We trained Support Vector Machine (SVM) and Convolutional Neural Network (CNN) models with the data. We measured accuracy of the trained models on the noisy dataset using ten-fold cross validation and separately on a set-aside manually annotated dataset. Results: About 13% of 117,730 clinical notes contained treatment plans sections with recognizable headings in the 1001 longitudinal patient records that were obtained from Cleveland Clinic under an IRB approval. We were able to extract and create a noisy training data of 13,492 plan sentences from the clinical notes. CNN achieved best F measures, 0.91 and 0.97 in the cross-validation and set-aside evaluation experiments respectively. SVM slightly underperformed with F measures of 0.89 and 0.96 in the same experiments. Conclusion: Our study showed that the training supervised learning models using noisy plan sentences was effective in identifying them in all clinical notes. More broadly, sections with informal headings in clinical notes can be a good source for generating effective training data.