 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Conditional Generative Adversarial Networks for Stereoscopic Hyperrealism in Surgical Training
Paper and Code


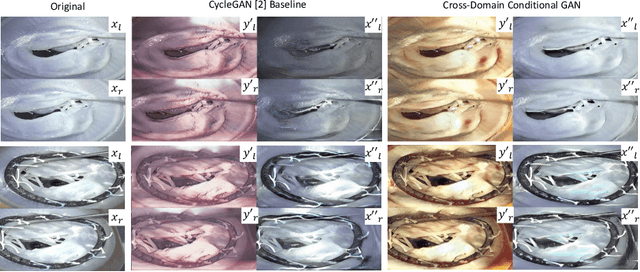
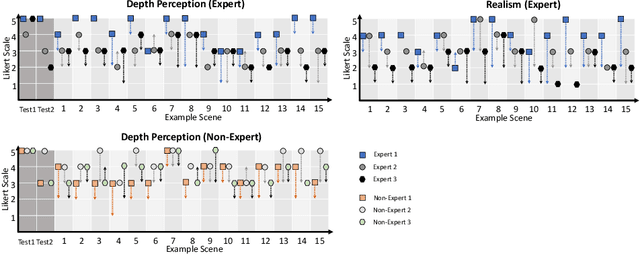
Phantoms for surgical training are able to mimic cutting and suturing properties and patient-individual shape of organs, but lack a realistic visual appearance that captures the heterogeneity of surgical scenes. In order to overcome this in endoscopic approaches, hyperrealistic concepts have been proposed to be used in an augmented reality-setting, which are based on deep image-to-image transformation methods. Such concepts are able to generate realistic representations of phantoms learned from real intraoperative endoscopic sequences. Conditioned on frames from the surgical training process, the learned models are able to generate impressive results by transforming unrealistic parts of the image (e.g.\ the uniform phantom texture is replaced by the more heterogeneous texture of the tissue). Image-to-image synthesis usually learns a mapping $G:X~\to~Y$ such that the distribution of images from $G(X)$ is indistinguishable from the distribution $Y$. However, it does not necessarily force the generated images to be consistent and without artifacts. In the endoscopic image domain this can affect depth cues and stereo consistency of a stereo image pair, which ultimately impairs surgical vision. We propose a cross-domain conditional generative adversarial network approach (GAN) that aims to generate more consistent stereo pairs. The results show substantial improvements in depth perception and realism evaluated by 3 domain experts and 3 medical students on a 3D monitor over the baseline method. In 84 of 90 instances our proposed method was preferred or rated equal to the baseline.