 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks for and by Interpolation
Paper and Code
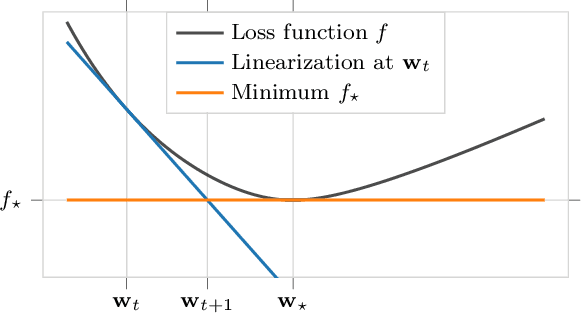
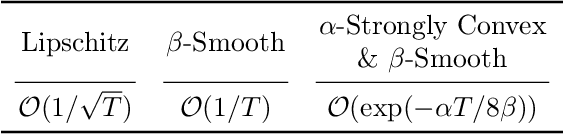
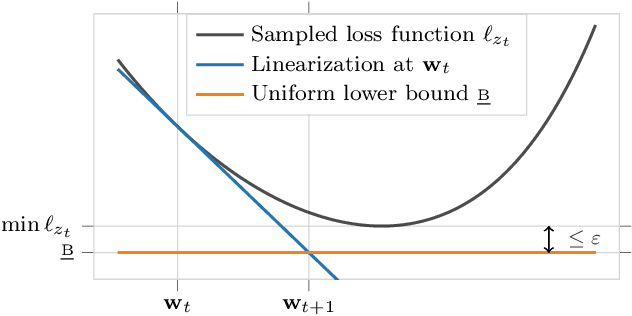

The majority of modern deep learning models are able to interpolate the data: the empirical loss can be driven near zero on all samples simultaneously. In this work, we explicitly exploit this interpolation property for the design of a new optimization algorithm for deep learning. Specifically, we use it to compute an adaptive learning-rate given a stochastic gradient direction. This results in the Adaptive Learning-rates for Interpolation with Gradients (ALI-G) algorithm. ALI-G retains the advantages of SGD, which are low computational cost and provable convergence in the convex setting. But unlike SGD, the learning-rate of ALI-G can be computed inexpensively in closed-form and does not require a manual schedule. We provide a detailed analysis of ALI-G in the stochastic convex setting with explicit convergence rates. In order to obtain good empirical performance in deep learning, we extend the algorithm to use a maximal learning-rate, which gives a single hyper-parameter to tune. We show that employing such a maximal learning-rate has an intuitive proximal interpretation and preserves all convergence guarantees. We provide experiments on a variety of architectures and tasks: (i) learning a differentiable neural computer; (ii) training a wide residual network on the SVHN data set; (iii) training a Bi-LSTM on the SNLI data set; and (iv) training wide residual networks and densely connected networks on the CIFAR data sets. We empirically show that ALI-G outperforms adaptive gradient methods such as Adam, and provides comparable performance with SGD, although SGD benefits from manual learning rate schedules. We release PyTorch and Tensorflow implementations of ALI-G as standalone optimizers that can be used as a drop-in replacement in existing code (code available at https://github.com/oval-group/ali-g ).