 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterized Structured Pruning for Deep Neural Networks
Paper and Code
Jun 12, 2019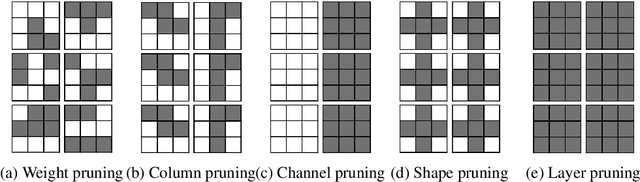

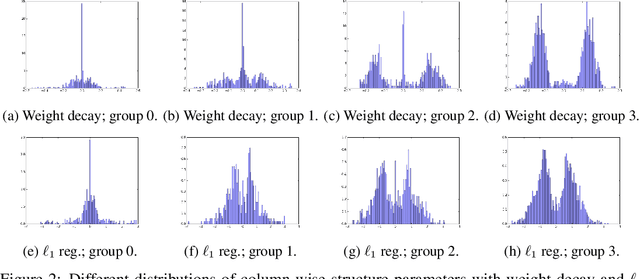
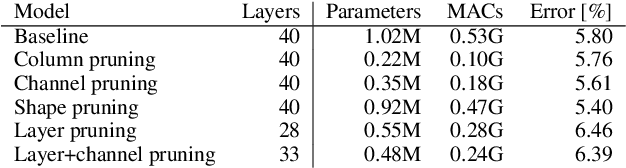
As a result of the growing size of Deep Neural Networks (DNNs), the gap to hardware capabilities in terms of memory and compute increases. To effectively compress DNNs, quantization and connection pruning are usually considered. However, unconstrained pruning usually leads to unstructured parallelism, which maps poorly to massively parallel processors, and substantially reduces the efficiency of general-purpose processors. Similar applies to quantization, which often requires dedicated hardware. We propose Parameterized Structured Pruning (PSP), a novel method to dynamically learn the shape of DNNs through structured sparsity. PSP parameterizes structures (e.g. channel- or layer-wise) in a weight tensor and leverages weight decay to learn a clear distinction between important and unimportant structures. As a result, PSP maintains prediction performance, creates a substantial amount of sparsity that is structured and, thus, easy and efficient to map to a variety of massively parallel processors, which are mandatory for utmost compute power and energy efficiency. PSP is experimentally validated on the popular CIFAR10/100 and ILSVRC2012 datasets using ResNet and DenseNet architectures, respectively.