 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalanced Off-Policy Evaluation in General Action Spaces
Paper and Code
Jun 13, 2019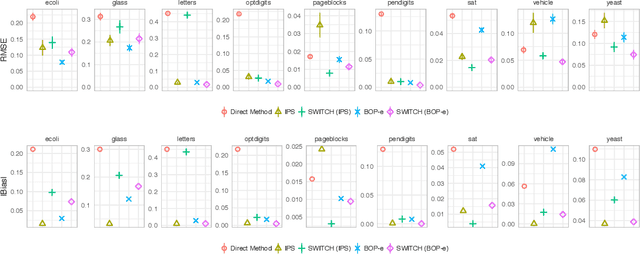

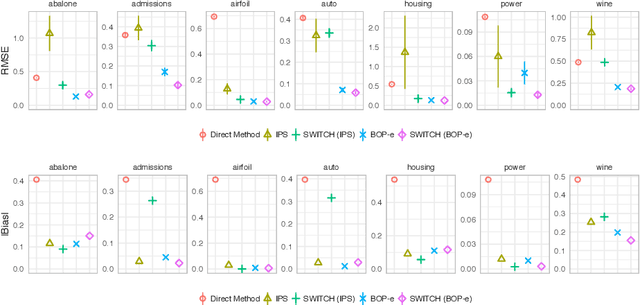
In many practical applications of contextual bandits, online learning is infeasible and practitioners must rely on off-policy evaluation (OPE) of logged data collected from prior policies. OPE generally consists of a combination of two components: (i) directly estimating a model of the reward given state and action and (ii) importance sampling. While recent work has made significant advances adaptively combining these two components, less attention has been paid to improving the quality of the importance weights themselves. In this work we present balancing off-policy evaluation (BOP-e), an importance sampling procedure that directly optimizes for balance and can be plugged into any OPE estimator that uses importance sampling. BOP-e directly estimates the importance sampling ratio via a classifier which attempts to distinguish state-action pairs from an observed versus a proposed policy. BOP-e can be applied to continuous, mixed, and multi-valued action spaces without modification and is easily scalable to many observations. Further, we show that minimization of regret in the constructed binary classification problem translates directly into minimizing regret in the off-policy evaluation task. Finally, we provide experimental evidence that BOP-e outperforms inverse propensity weighting-based approaches for offline evaluation of policies in the contextual bandit setting under both discrete and continuous action spaces.