 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Ambiguity Detection
Paper and Code
May 28, 2019
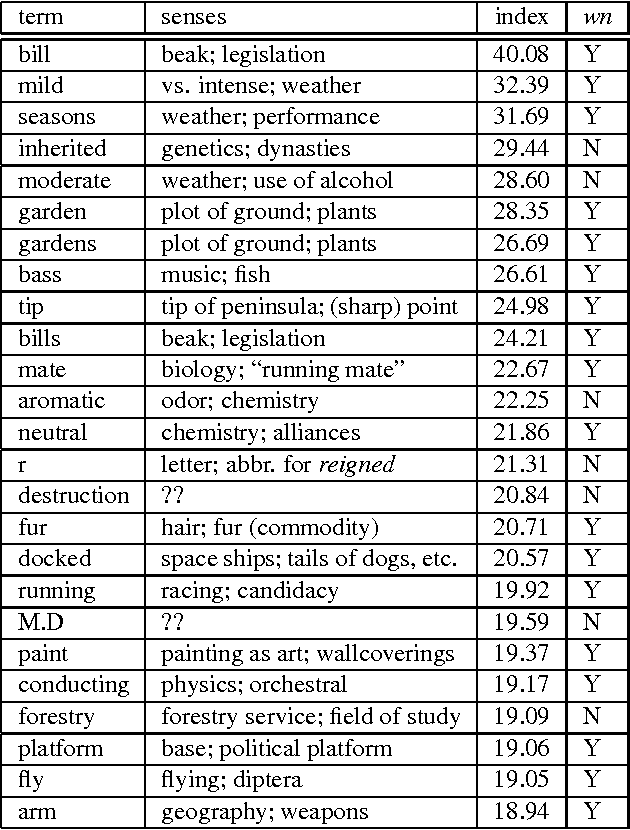
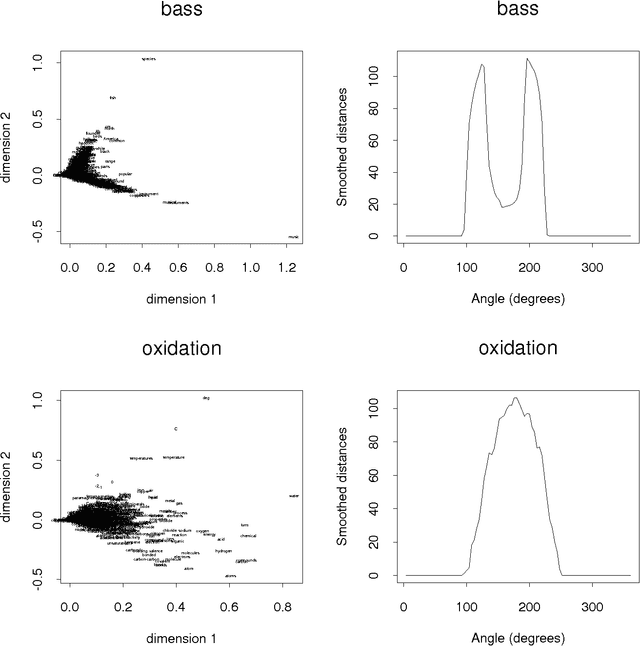
Most work on sense disambiguation presumes that one knows beforehand -- e.g. from a thesaurus -- a set of polysemous terms. But published lists invariably give only partial coverage. For example, the English word tan has several obvious senses, but one may overlook the abbreviation for tangent. In this paper, we present an algorithm for identifying interesting polysemous terms and measuring their degree of polysemy, given an unlabeled corpus. The algorithm involves: (i) collecting all terms within a k-term window of the target term; (ii) computing the inter-term distances of the contextual terms, and reducing the multi-dimensional distance space to two dimensions using standard methods; (iii) converting the two-dimensional representation into radial coordinates and using isotonic/antitonic regression to compute the degree to which the distribution deviates from a single-peak model. The amount of deviation is the proposed polysemy index