 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Gradient Clipping and Adaptive Scaling with a Relaxed Smoothness Condition
Paper and Code
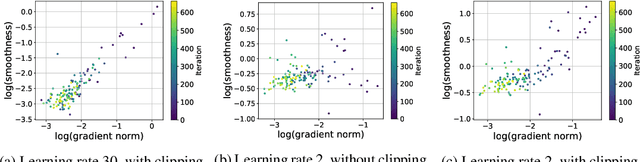
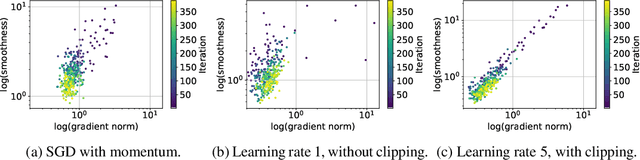
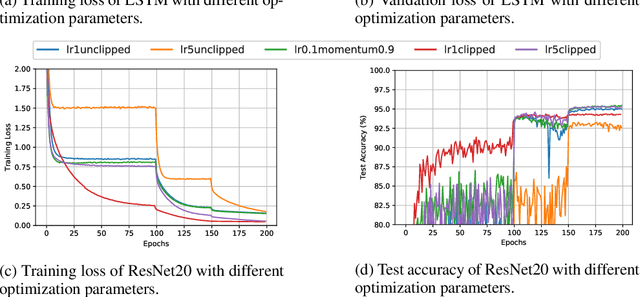

We provide a theoretical explanation for the fast convergence of gradient clipping and adaptively scaled gradient methods commonly used in neural network training. Our analysis is based on a novel relaxation of gradient smoothness conditions that is weaker than the commonly used Lipschitz smoothness assumption. We validate the new smoothness condition in experiments on large-scale neural network training applications where adaptively-scaled methods have been empirically shown to outperform standard gradient based algorithms. Under this new smoothness condition, we prove that two popular adaptively scaled methods, \emph{gradient clipping} and \emph{normalized gradient}, converge faster than the theoretical lower bound of fixed-step gradient descent. We verify this fast convergence empirically in neural network training for language modeling and image classification.