 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Policies from Human Data for Skat
Paper and Code
May 27, 2019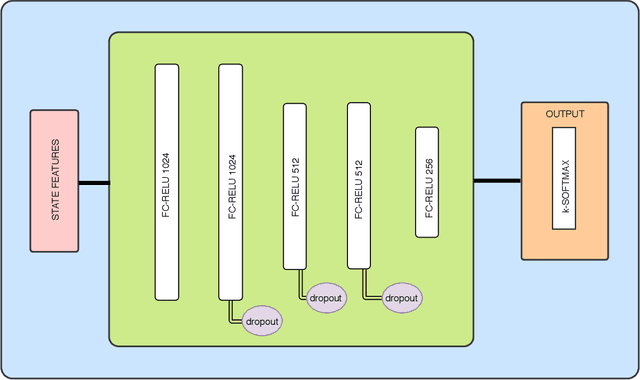
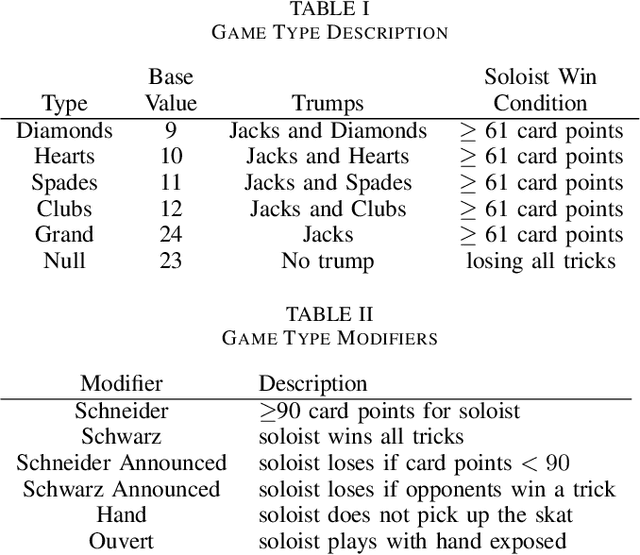
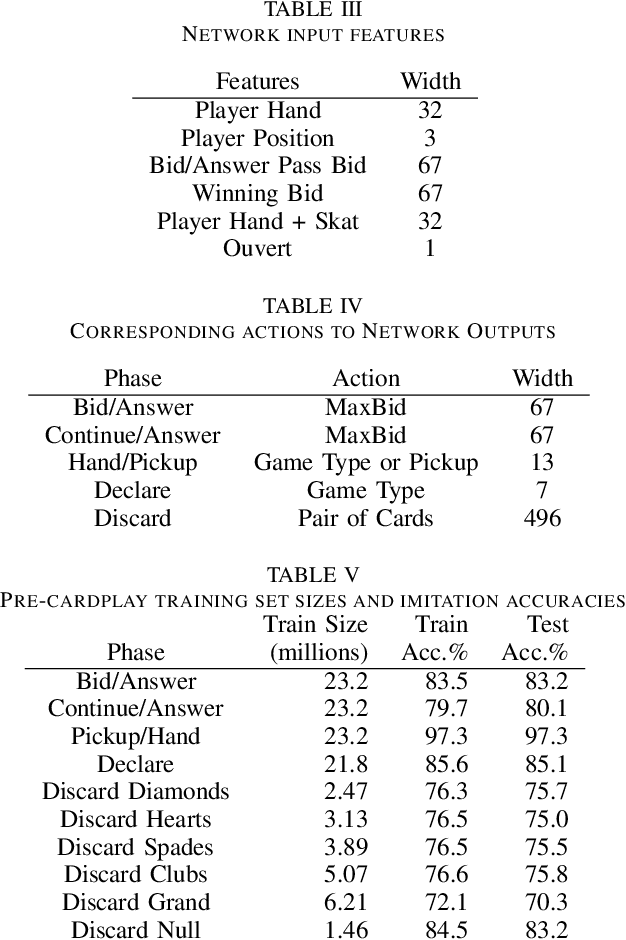
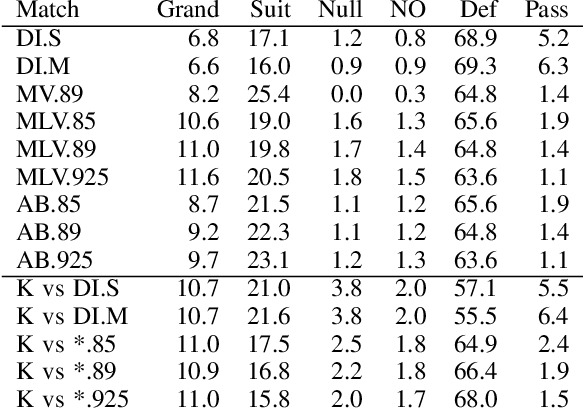
Decision-making in large imperfect information games is difficult. Thanks to recent success in Poker, Counterfactual Regret Minimization (CFR) methods have been at the forefront of research in these games. However, most of the success in large games comes with the use of a forward model and powerful state abstractions. In trick-taking card games like Bridge or Skat, large information sets and an inability to advance the simulation without fully determinizing the state make forward search problematic. Furthermore, state abstractions can be especially difficult to construct because the precise holdings of each player directly impact move values. In this paper we explore learning model-free policies for Skat from human game data using deep neural networks (DNN). We produce a new state-of-the-art system for bidding and game declaration by introducing methods to a) directly vary the aggressiveness of the bidder and b) declare games based on expected value while mitigating issues with rarely observed state-action pairs. Although cardplay policies learned through imitation are slightly weaker than the current best search-based method, they run orders of magnitude faster. We also explore how these policies could be learned directly from experience in a reinforcement learning setting and discuss the value of incorporating human data for this task.