 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Meta-Learning: Toward more flexible deep-learning models
Paper and Code
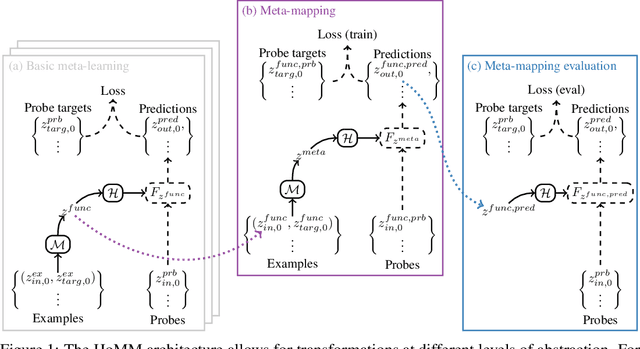
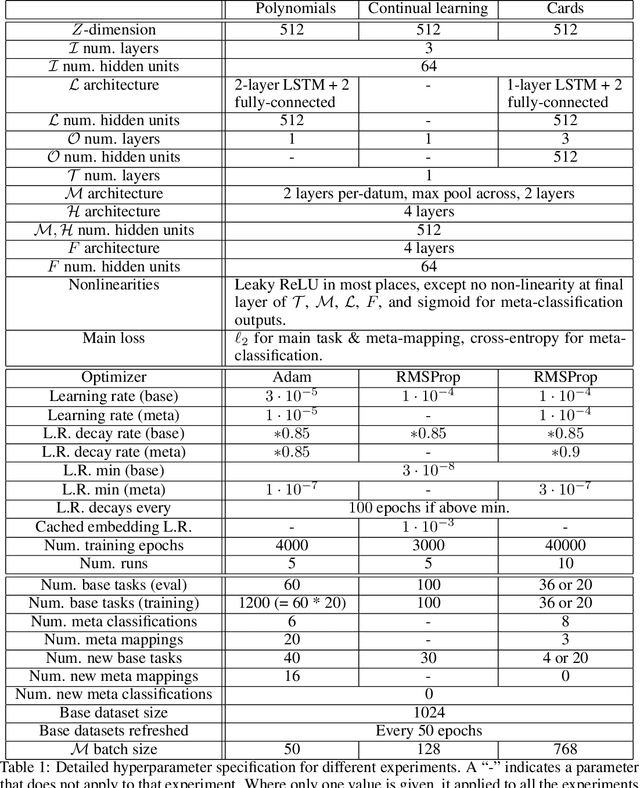
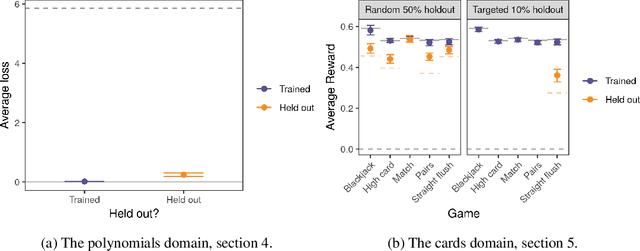
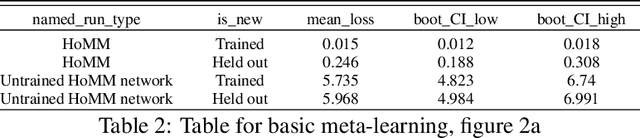
How can deep learning systems flexibly reuse their knowledge? Toward this goal, we propose a new class of challenges, and a class of architectures that can solve them. The challenges are meta-mappings, which involve systematically transforming task behaviors to adapt to new tasks zero-shot. We suggest that the key to achieving these challenges is representing the task being performed along with the computations used to perform it. We therefore draw inspiration from meta-learning and functional programming to propose a class of Embedded Meta-Learning (EML) architectures that represent both data and tasks in a shared latent space. EML architectures are applicable to any type of machine learning task, including supervised learning and reinforcement learning. We demonstrate the flexibility of these architectures by showing that they can perform meta-mappings, i.e. that they can exhibit zero-shot remapping of behavior to adapt to new tasks.