 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fully Dense Neural Networks for Image Semantic Segmentation
Paper and Code
May 22, 2019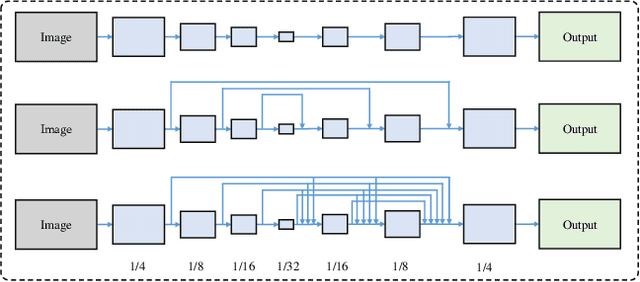
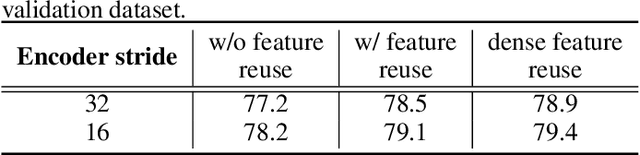

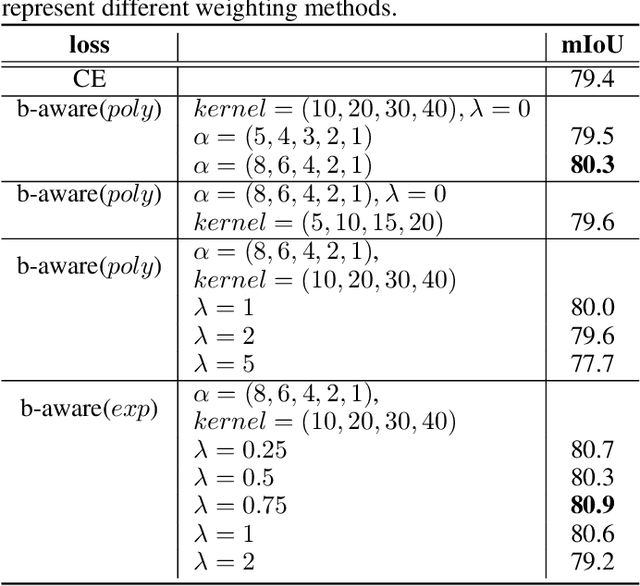
Semantic segmentation is pixel-wise classification which retains critical spatial information. The "feature map reuse" has been commonly adopted in CNN based approaches to take advantage of feature maps in the early layers for the later spatial reconstruction. Along this direction, we go a step further by proposing a fully dense neural network with an encoder-decoder structure that we abbreviate as FDNet. For each stage in the decoder module, feature maps of all the previous blocks are adaptively aggregated to feed-forward as input. On the one hand, it reconstructs the spatial boundaries accurately. On the other hand, it learns more efficiently with the more efficient gradient backpropagation. In addition, we propose the boundary-aware loss function to focus more attention on the pixels near the boundary, which boosts the "hard examples" labeling. We have demonstrated the best performance of the FDNet on the two benchmark datasets: PASCAL VOC 2012, NYUDv2 over previous works when not considering training on other datasets.