Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Universal Task-Specific BERT
Paper and Code
May 16, 2019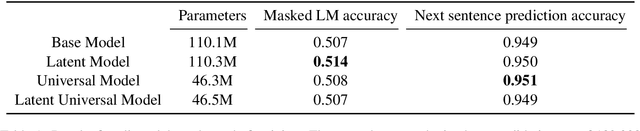
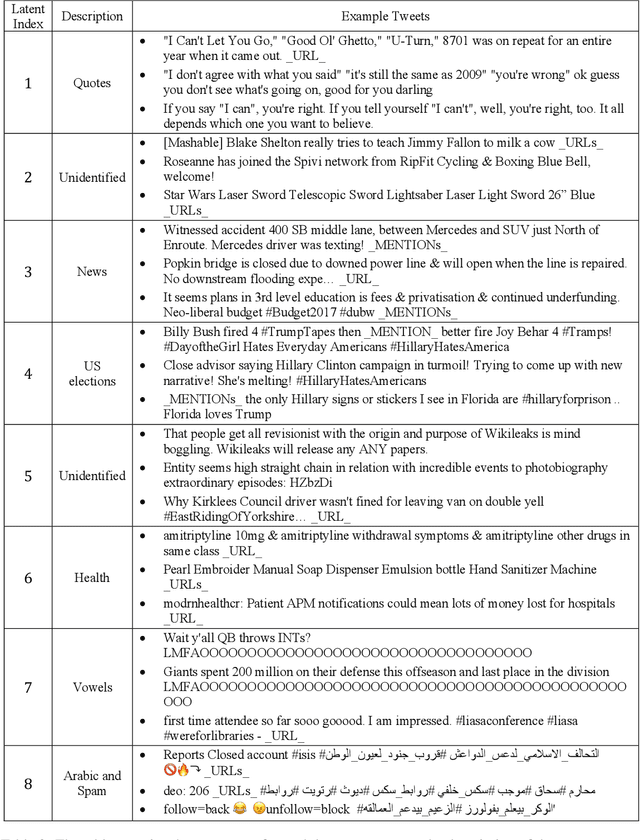
This paper describes a language representation model which combines the Bidirectional Encoder Representations from Transformers (BERT) learning mechanism described in Devlin et al. (2018) with a generalization of the Universal Transformer model described in Dehghani et al. (2018). We further improve this model by adding a latent variable that represents the persona and topics of interests of the writer for each training example. We also describe a simple method to improve the usefulness of our language representation for solving problems in a specific domain at the expense of its ability to generalize to other fields. Finally, we release a pre-trained language representation model for social texts that was trained on 100 million tweets.
* 6 pages, 2 figures
View paper on