 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Residual Output Layers for Neural Language Generation
Paper and Code
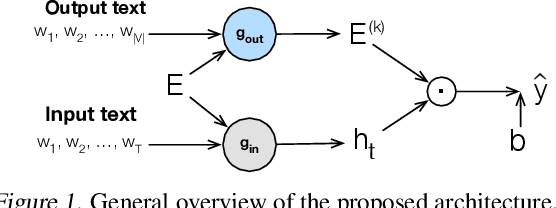
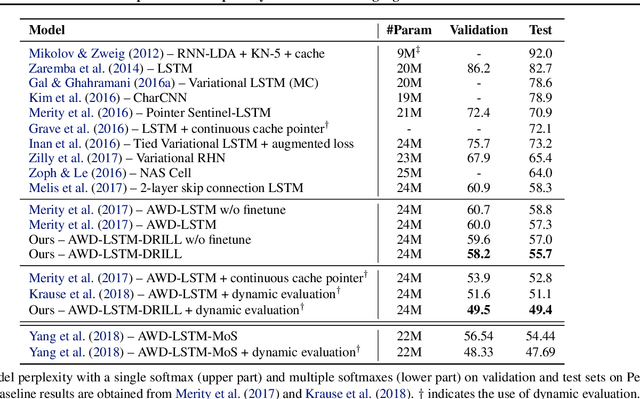
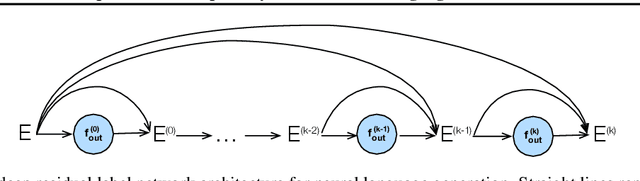
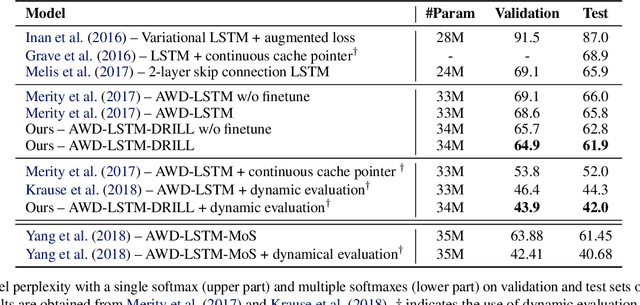
Many tasks, including language generation, benefit from learning the structure of the output space, particularly when the space of output labels is large and the data is sparse. State-of-the-art neural language models indirectly capture the output space structure in their classifier weights since they lack parameter sharing across output labels. Learning shared output label mappings helps, but existing methods have limited expressivity and are prone to overfitting. In this paper, we investigate the usefulness of more powerful shared mappings for output labels, and propose a deep residual output mapping with dropout between layers to better capture the structure of the output space and avoid overfitting. Evaluations on three language generation tasks show that our output label mapping can match or improve state-of-the-art recurrent and self-attention architectures, and suggest that the classifier does not necessarily need to be high-rank to better model natural language if it is better at capturing the structure of the output space.