 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask deep learning with spectral knowledge for hyperspectral image classification
Paper and Code
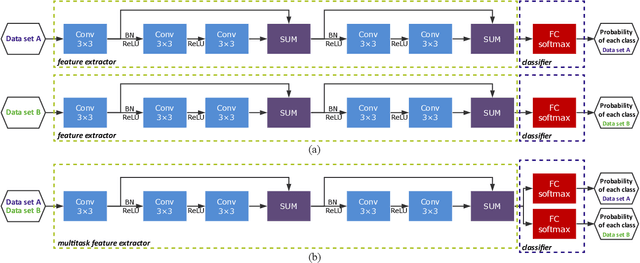

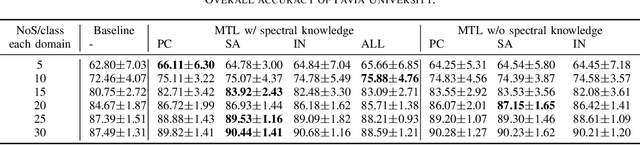

In this letter, we introduce multitask learning to hyperspectral image classification. Deep learning models have achieved promising results on hyperspectral image classification, but their performance highly rely on sufficient labeled samples, which are scarce on hyperspectral images. However, samples from multiple data sets might be sufficient to train one deep learning model, thereby improving its performance. To do so, spectral knowledge is introduced to ensure that the shared features are similar across domains. Four hyperspectral data sets were used in the experiments. We achieved better classification accuracies on three data sets (Pavia University, Indian Pines, and Pavia Center) originally with poor results or simple classification systems and competitive results on Salinas Valley data originally with a complex classification system. Spectral knowledge is useful to prevent the deep network from overfitting when the training samples were scarce. The proposed method successfully utilized samples from multiple data sets to increase its performance.