 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlay and Prune: Adaptive Filter Pruning for Deep Model Compression
Paper and Code
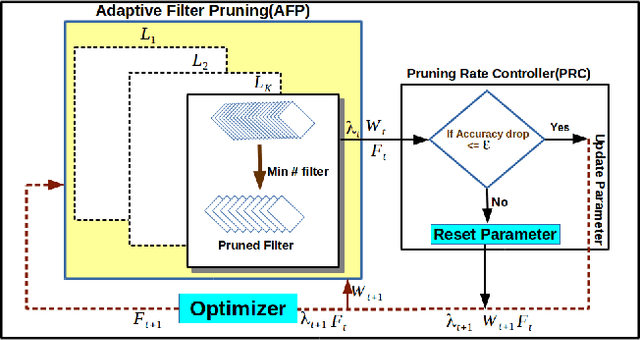
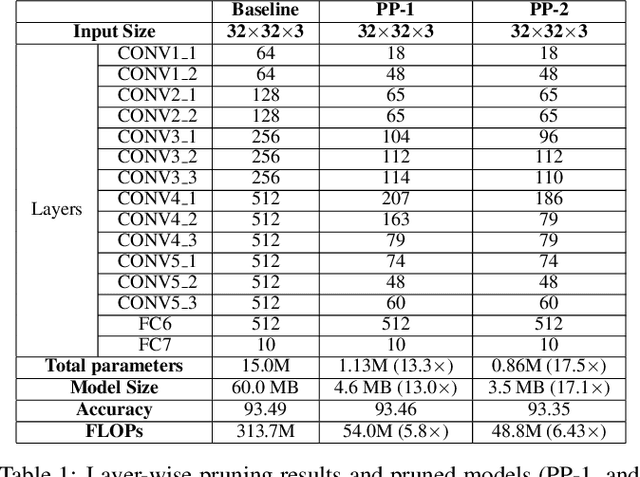
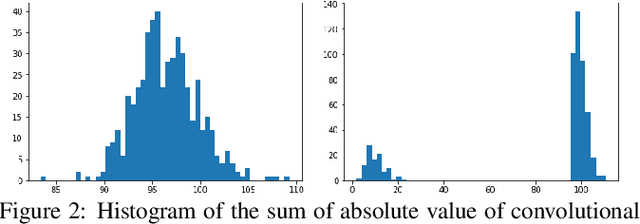
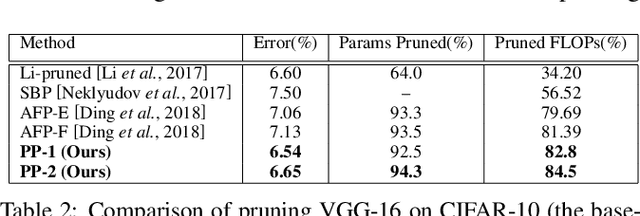
While convolutional neural networks (CNN) have achieved impressive performance on various classification/recognition tasks, they typically consist of a massive number of parameters. This results in significant memory requirement as well as computational overheads. Consequently, there is a growing need for filter-level pruning approaches for compressing CNN based models that not only reduce the total number of parameters but reduce the overall computation as well. We present a new min-max framework for filter-level pruning of CNNs. Our framework, called Play and Prune (PP), jointly prunes and fine-tunes CNN model parameters, with an adaptive pruning rate, while maintaining the model's predictive performance. Our framework consists of two modules: (1) An adaptive filter pruning (AFP) module, which minimizes the number of filters in the model; and (2) A pruning rate controller (PRC) module, which maximizes the accuracy during pruning. Moreover, unlike most previous approaches, our approach allows directly specifying the desired error tolerance instead of pruning level. Our compressed models can be deployed at run-time, without requiring any special libraries or hardware. Our approach reduces the number of parameters of VGG-16 by an impressive factor of 17.5X, and number of FLOPS by 6.43X, with no loss of accuracy, significantly outperforming other state-of-the-art filter pruning methods.