 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Functional Dependencies with Sparse Regression
Paper and Code


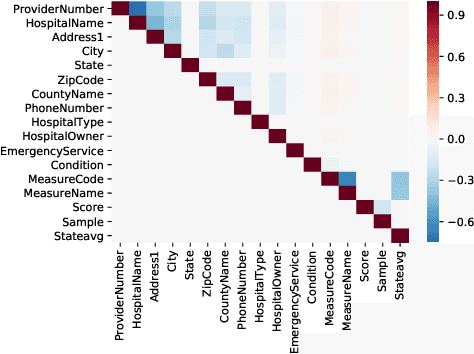
We study the problem of discovering functional dependencies (FD) from a noisy dataset. We focus on FDs that correspond to statistical dependencies in a dataset and draw connections between FD discovery and structure learning in probabilistic graphical models. We show that discovering FDs from a noisy dataset is equivalent to learning the structure of a graphical model over binary random variables, where each random variable corresponds to a functional of the dataset attributes. We build upon this observation to introduce AutoFD a conceptually simple framework in which learning functional dependencies corresponds to solving a sparse regression problem. We show that our methods can recover true functional dependencies across a diverse array of real-world and synthetic datasets, even in the presence of noisy or missing data. We find that AutoFD scales to large data instances with millions of tuples and hundreds of attributes while it yields an average F1 improvement of 2 times against state-of-the-art FD discovery methods.