 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Feature Compression via Submodular Optimization
Paper and Code
Apr 30, 2019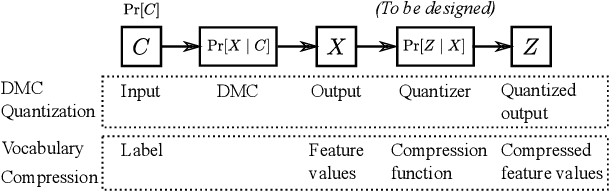
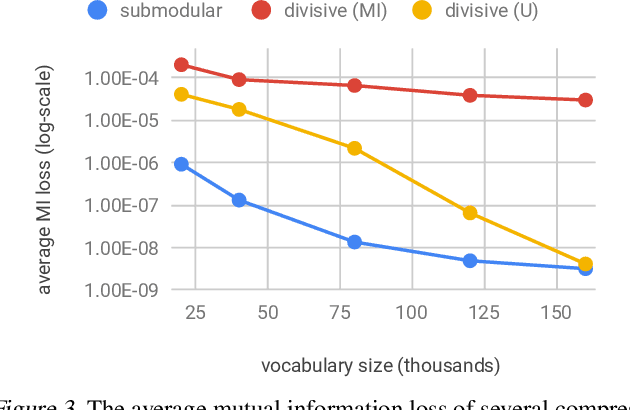
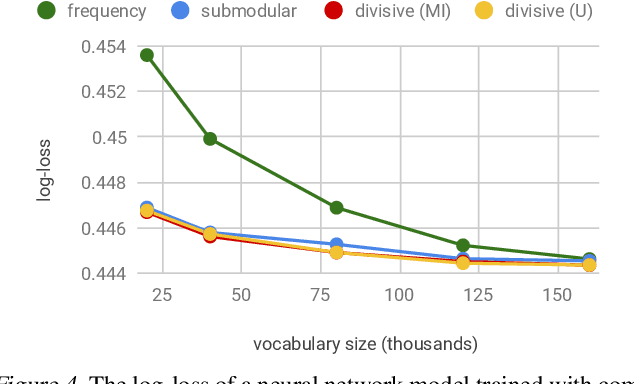
In the era of big data, learning from categorical features with very large vocabularies (e.g., 28 million for the Criteo click prediction dataset) has become a practical challenge for machine learning researchers and practitioners. We design a highly-scalable vocabulary compression algorithm that seeks to maximize the mutual information between the compressed categorical feature and the target binary labels and we furthermore show that its solution is guaranteed to be within a $1-1/e \approx 63\%$ factor of the global optimal solution. To achieve this, we introduce a novel re-parametrization of the mutual information objective, which we prove is submodular, and design a data structure to query the submodular function in amortized $O(\log n )$ time (where $n$ is the input vocabulary size). Our complete algorithm is shown to operate in $O(n \log n )$ time. Additionally, we design a distributed implementation in which the query data structure is decomposed across $O(k)$ machines such that each machine only requires $O(\frac n k)$ space, while still preserving the approximation guarantee and using only logarithmic rounds of computation. We also provide analysis of simple alternative heuristic compression methods to demonstrate they cannot achieve any approximation guarantee. Using the large-scale Criteo learning task, we demonstrate better performance in retaining mutual information and also verify competitive learning performance compared to other baseline methods.