 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Why Should You Trust My Explanation?" Understanding Uncertainty in LIME Explanations
Paper and Code
Jun 04, 2019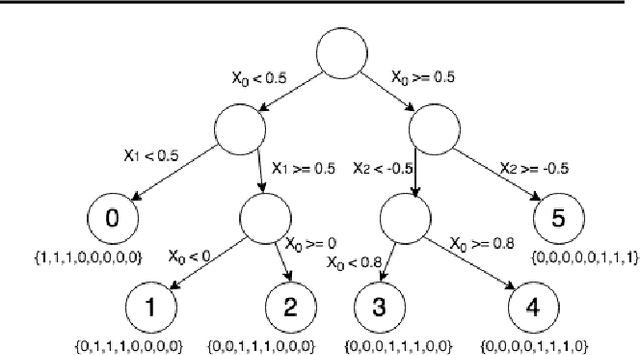
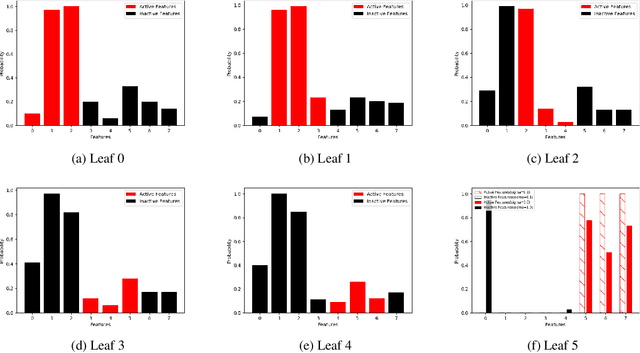
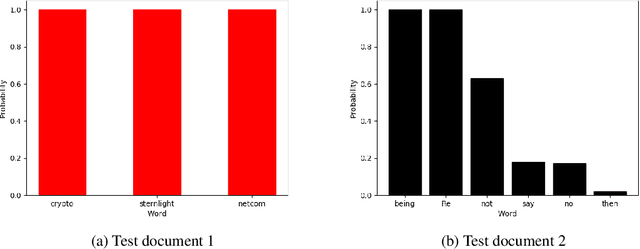
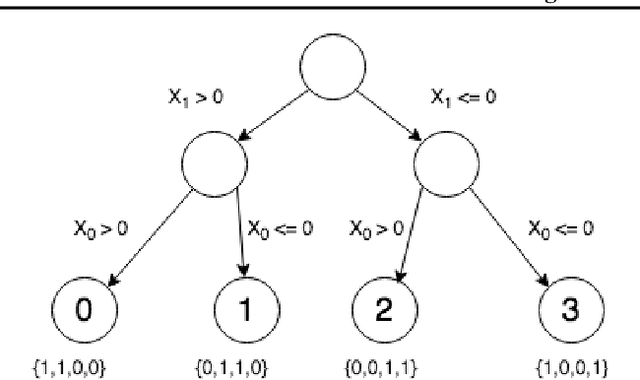
Methods for interpreting machine learning black-box models increase the outcomes' transparency and in turn generates insight into the reliability and fairness of the algorithms. However, the interpretations themselves could contain significant uncertainty that undermines the trust in the outcomes and raises concern about the model's reliability. Focusing on the method "Local Interpretable Model-agnostic Explanations" (LIME), we demonstrate the presence of two sources of uncertainty, namely the randomness in its sampling procedure and the variation of interpretation quality across different input data points. Such uncertainty is present even in models with high training and test accuracy. We apply LIME to synthetic data and two public data sets, text classification in 20 Newsgroup and recidivism risk-scoring in COMPAS, to support our argument.