 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Recognizing Phrase Translation Processes: Experiments on English-French
Paper and Code
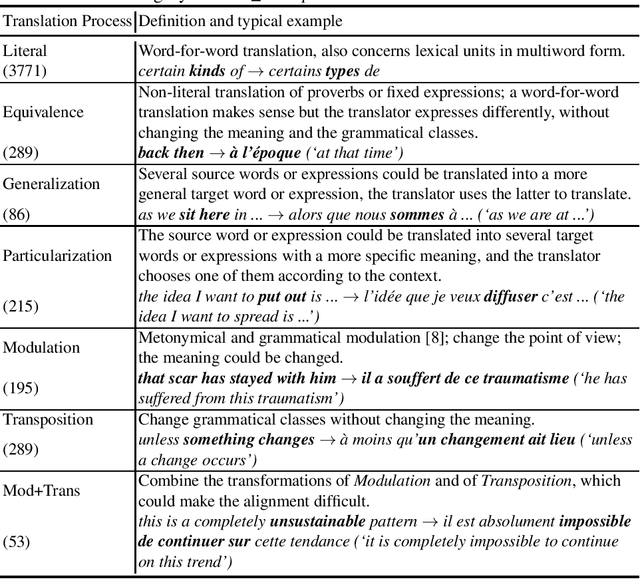
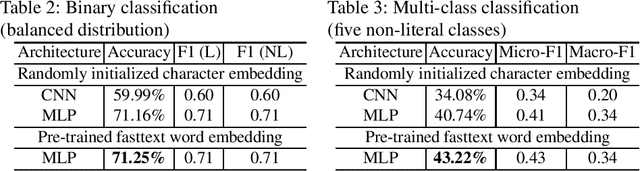
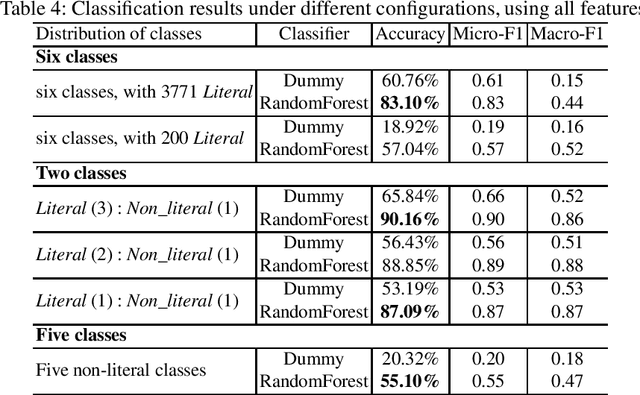

When translating phrases (words or group of words), human translators, consciously or not, resort to different translation processes apart from the literal translation, such as Idiom Equivalence, Generalization, Particularization, Semantic Modulation, etc. Translators and linguists (such as Vinay and Darbelnet, Newmark, etc.) have proposed several typologies to characterize the different translation processes. However, to the best of our knowledge, there has not been effort to automatically classify these fine-grained translation processes. Recently, an English-French parallel corpus of TED Talks has been manually annotated with translation process categories, along with established annotation guidelines. Based on these annotated examples, we propose an automatic classification of translation processes at subsentential level. Experimental results show that we can distinguish non-literal translation from literal translation with an accuracy of 87.09%, and 55.20% for classifying among five non-literal translation processes. This work demonstrates that it is possible to automatically classify translation processes. Even with a small amount of annotated examples, our experiments show the directions that we can follow in future work. One of our long term objectives is leveraging this automatic classification to better control paraphrase extraction from bilingual parallel corpora.