 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Pruning Method for Neural Networks
Paper and Code
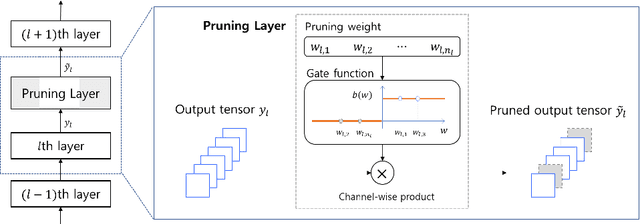
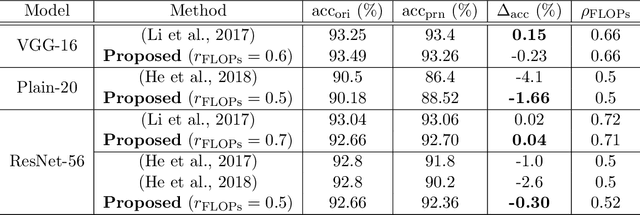
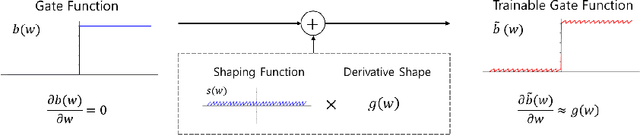
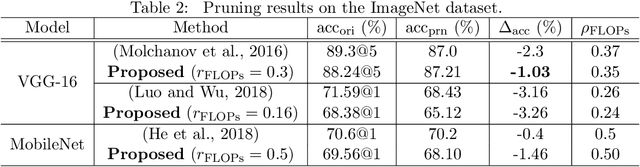
Architecture optimization is a promising technique to find an efficient neural network to meet certain requirements, which is usually a problem of selections. This paper introduces a concept of a trainable gate function and proposes a channel pruning method which finds automatically the optimal combination of channels using a simple gradient descent training procedure. The trainable gate function, which confers a differentiable property to discrete-valued variables, allows us to directly optimize loss functions that include discrete values such as the number of parameters or FLOPs that are generally non-differentiable. Channel pruning can be applied simply by appending trainable gate functions to each intermediate output tensor followed by fine-tuning the overall model, using any gradient-based training methods. Our experiments show that the proposed method can achieve better compression results on various models. For instance, our proposed method compresses ResNet-56 on CIFAR-10 dataset by half in terms of the number of FLOPs without accuracy drop.