 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Cleaning for Accurate, Fair, and Robust Models: A Big Data - AI Integration Approach
Paper and Code
Apr 22, 2019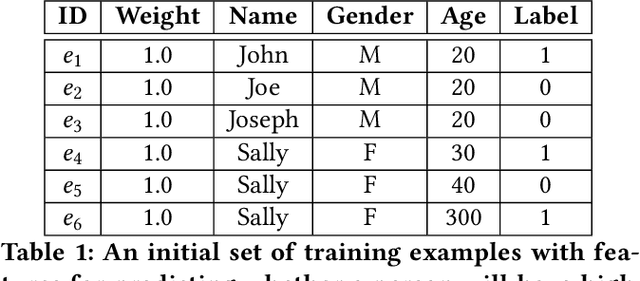
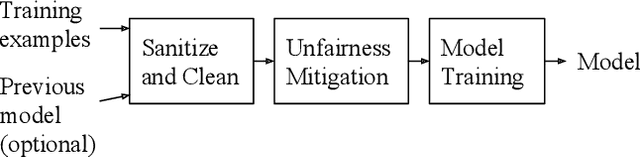
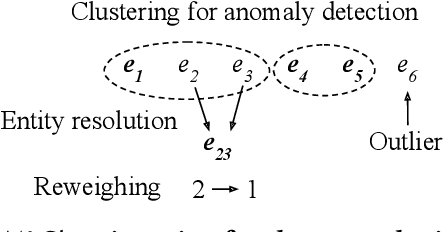
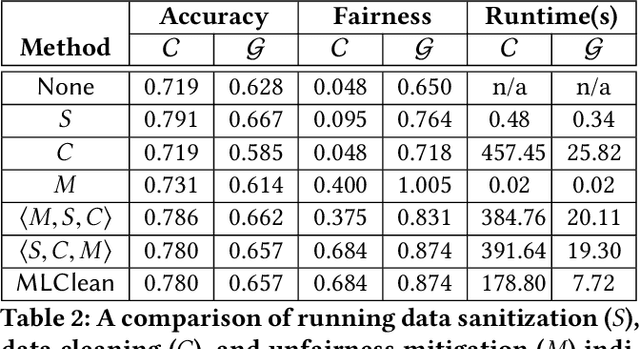
The wide use of machine learning is fundamentally changing the software development paradigm (a.k.a. Software 2.0) where data becomes a first-class citizen, on par with code. As machine learning is used in sensitive applications, it becomes imperative that the trained model is accurate, fair, and robust to attacks. While many techniques have been proposed to improve the model training process (in-processing approach) or the trained model itself (post-processing), we argue that the most effective method is to clean the root cause of error: the data the model is trained on (pre-processing). Historically, there are at least three research communities that have been separately studying this problem: data management, machine learning (model fairness), and security. Although a significant amount of research has been done by each community, ultimately the same datasets must be preprocessed, and there is little understanding how the techniques relate to each other and can possibly be integrated. We contend that it is time to extend the notion of data cleaning for modern machine learning needs. We identify dependencies among the data preprocessing techniques and propose MLClean, a unified data cleaning framework that integrates the techniques and helps train accurate and fair models. This work is part of a broader trend of Big data -- Artificial Intelligence (AI) integration.