 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Explainability: Leveraging Interpretability for Improved Adversarial Learning
Paper and Code
Apr 21, 2019
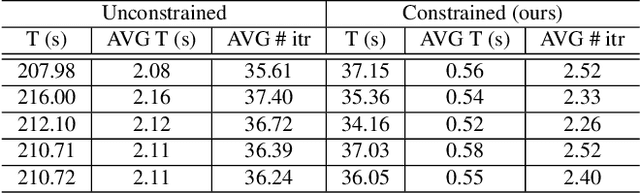

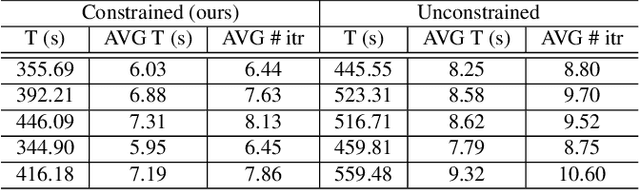
In this study, we propose the leveraging of interpretability for tasks beyond purely the purpose of explainability. In particular, this study puts forward a novel strategy for leveraging gradient-based interpretability in the realm of adversarial examples, where we use insights gained to aid adversarial learning. More specifically, we introduce the concept of spatially constrained one-pixel adversarial perturbations, where we guide the learning of such adversarial perturbations towards more susceptible areas identified via gradient-based interpretability. Experimental results using different benchmark datasets show that such a spatially constrained one-pixel adversarial perturbation strategy can noticeably improve the speed of convergence as well as produce successful attacks that were also visually difficult to perceive, thus illustrating an effective use of interpretability methods for tasks outside of the purpose of purely explainability.