 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discovery of Multimodal Links in Multi-Image, Multi-Sentence Documents
Paper and Code
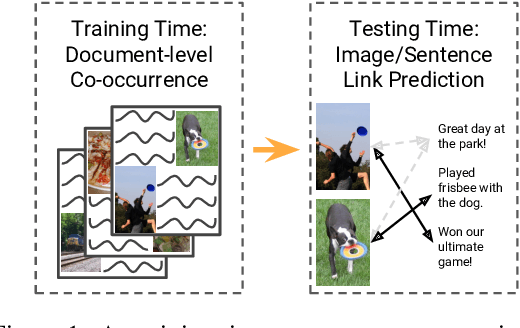
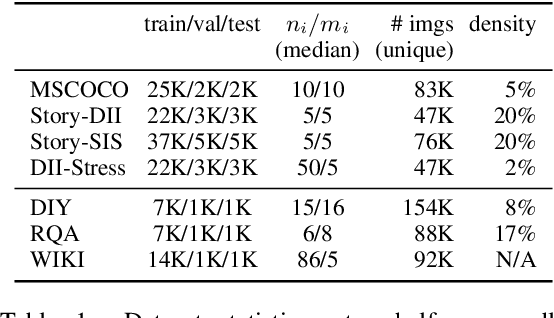

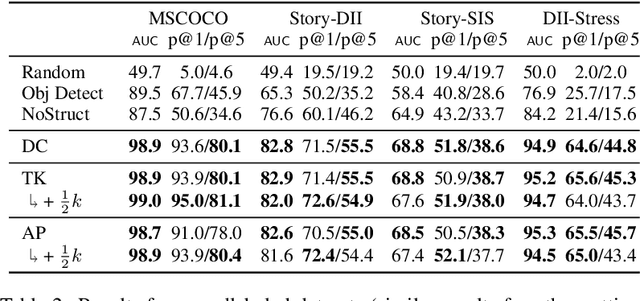
Images and text co-occur everywhere on the web, but explicit links between images and sentences (or other intra-document textual units) are often not annotated by users. We present algorithms that successfully discover image-sentence relationships without relying on any explicit multimodal annotation. We explore several variants of our approach on seven datasets of varying difficulty, ranging from images that were captioned post hoc by crowd-workers to naturally-occurring user-generated multimodal documents, wherein correspondences between illustrations and individual textual units may not be one-to-one. We find that a structured training objective based on identifying whether sets of images and sentences co-occur in documents can be sufficient to predict links between specific sentences and specific images within the same document at test time.