 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Reducing Gender Bias in Word-Level Language Models
Paper and Code
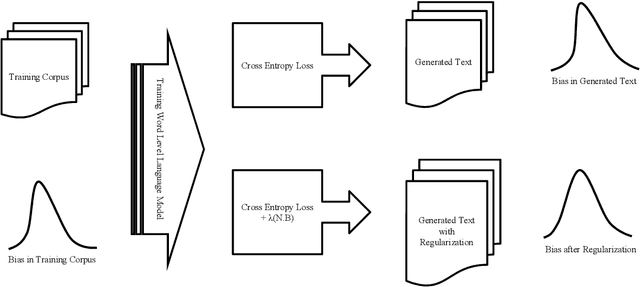
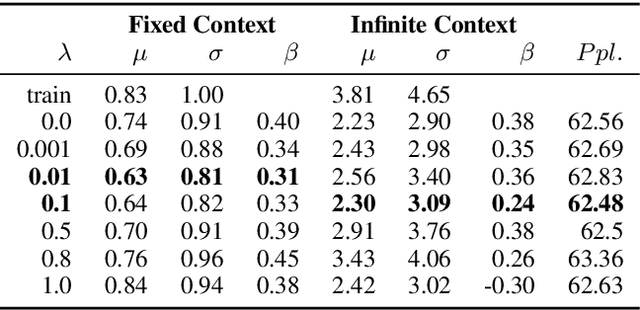
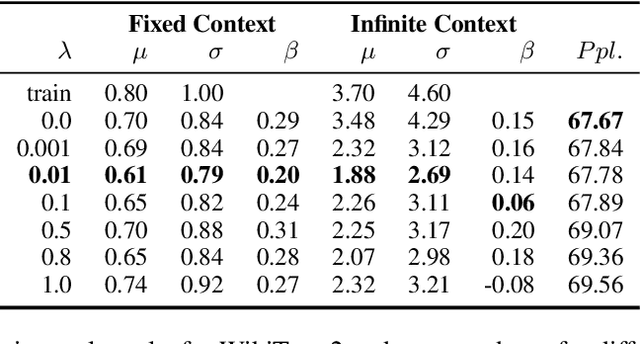
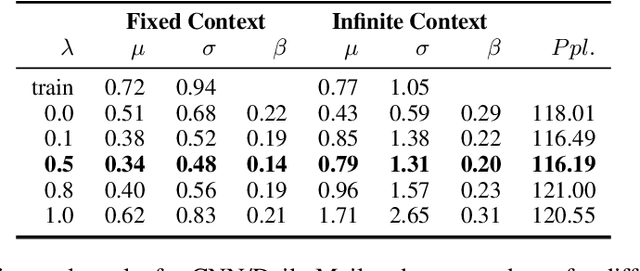
Many text corpora exhibit socially problematic biases, which can be propagated or amplified in the models trained on such data. For example, doctor cooccurs more frequently with male pronouns than female pronouns. In this study we (i) propose a metric to measure gender bias; (ii) measure bias in a text corpus and the text generated from a recurrent neural network language model trained on the text corpus; (iii) propose a regularization loss term for the language model that minimizes the projection of encoder-trained embeddings onto an embedding subspace that encodes gender; (iv) finally, evaluate efficacy of our proposed method on reducing gender bias. We find this regularization method to be effective in reducing gender bias up to an optimal weight assigned to the loss term, beyond which the model becomes unstable as the perplexity increases. We replicate this study on three training corpora---Penn Treebank, WikiText-2, and CNN/Daily Mail---resulting in similar conclusions.