 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-based Pose-aware Regulation for Video-based Person Re-identification
Paper and Code
Mar 27, 2019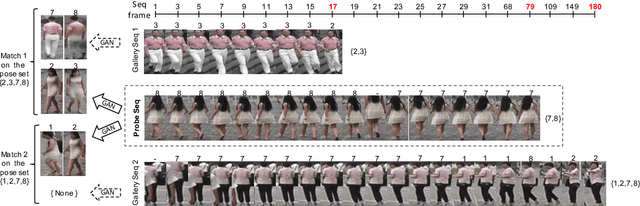
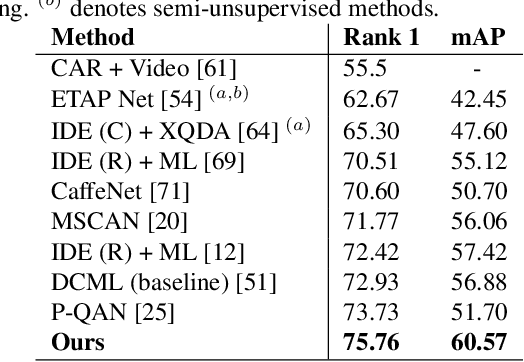
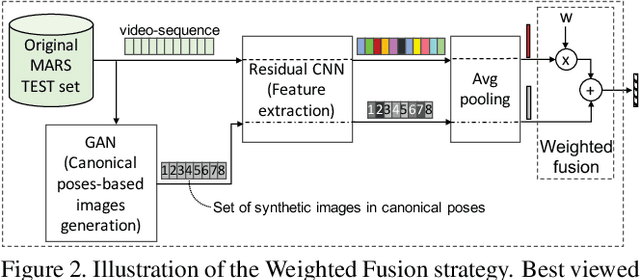
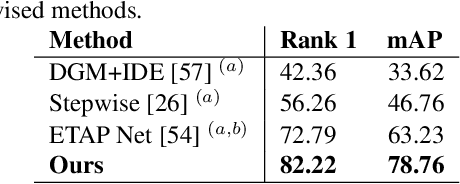
Video-based person re-identification deals with the inherent difficulty of matching unregulated sequences with different length and with incomplete target pose/viewpoint structure. Common approaches operate either by reducing the problem to the still images case, facing a significant information loss, or by exploiting inter-sequence temporal dependencies as in Siamese Recurrent Neural Networks or in gait analysis. However, in all cases, the inter-sequences pose/viewpoint misalignment is not considered, and the existing spatial approaches are mostly limited to the still images context. To this end, we propose a novel approach that can exploit more effectively the rich video information, by accounting for the role that the changing pose/viewpoint factor plays in the sequences matching process. Specifically, our approach consists of two components. The first one attempts to complement the original pose-incomplete information carried by the sequences with synthetic GAN-generated images, and fuse their feature vectors into a more discriminative viewpoint-insensitive embedding, namely Weighted Fusion (WF). Another one performs an explicit pose-based alignment of sequence pairs to promote coherent feature matching, namely Weighted-Pose Regulation (WPR). Extensive experiments on two large video-based benchmark datasets show that our approach outperforms considerably existing methods.