 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially-Adaptive Residual Networks for Efficient Image and Video Deblurring
Paper and Code
Mar 29, 2019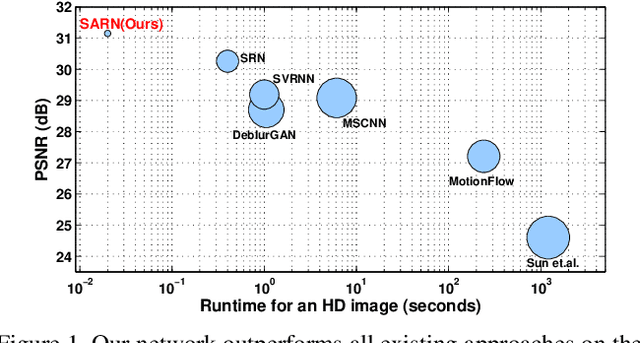

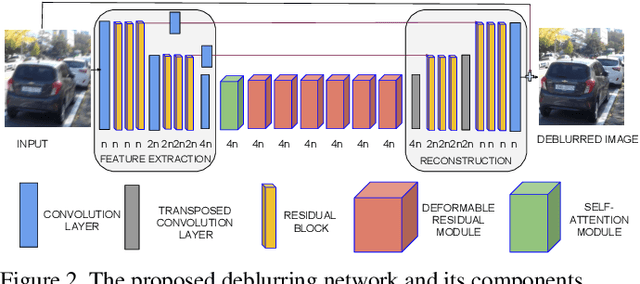
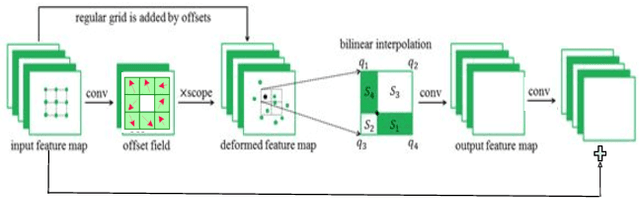
In this paper, we address the problem of dynamic scene deblurring in the presence of motion blur. Restoration of images affected by severe blur necessitates a network design with a large receptive field, which existing networks attempt to achieve through a simple increment in the number of generic convolution layers, kernel-size, or the scales at which the image is processed. However, increasing the network capacity in this manner comes at the expense of an increase in model size and inference time, and ignoring the non-uniform nature of blur. We present a new architecture composed of spatially adaptive residual learning modules that implicitly discover the spatially varying shifts responsible for non-uniform blur in the input image and learn to modulate the filters. This capability is complemented by a self-attentive module which captures non-local relationships among the intermediate features and enhances the receptive field. We then incorporate a spatiotemporal recurrent module in the design to also facilitate efficient video deblurring. Our networks can implicitly model the spatially-varying deblurring process while dispensing with multi-scale processing and large filters entirely. Extensive qualitative and quantitative comparisons with prior art on benchmark dynamic scene deblurring datasets clearly demonstrate the superiority of the proposed networks via a reduction in model-size and significant improvements in accuracy and speed, enabling almost real-time deblurring.