 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmless interpolation of noisy data in regression
Paper and Code
Mar 21, 2019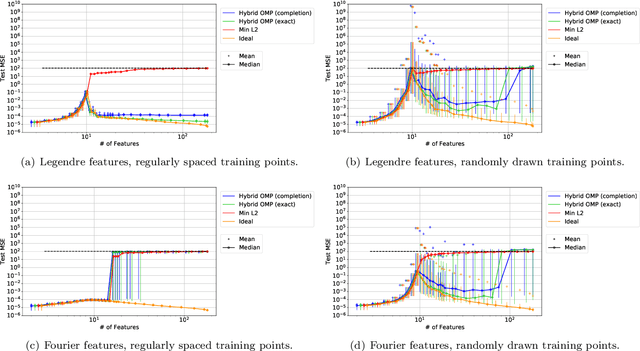
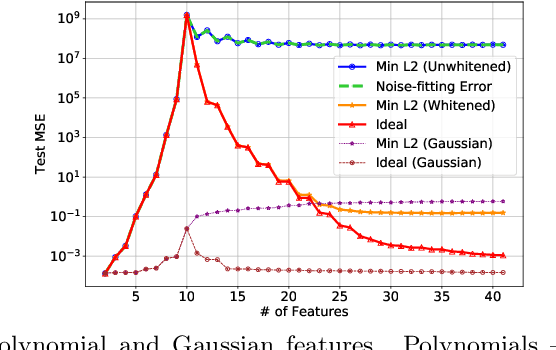
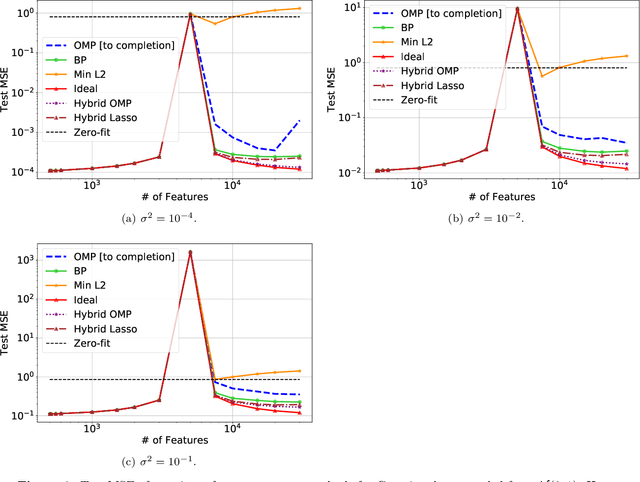
A continuing mystery in understanding the empirical success of deep neural networks has been in their ability to achieve zero training error and yet generalize well, even when the training data is noisy and there are more parameters than data points. We investigate this "overparametrization" phenomena in the classical underdetermined linear regression problem, where all solutions that minimize training error interpolate the data, including noise. We give a bound on how well such interpolative solutions can generalize to fresh test data, and show that this bound generically decays to zero with the number of extra features, thus characterizing an explicit benefit of overparameterization. For appropriately sparse linear models, we provide a hybrid interpolating scheme (combining classical sparse recovery schemes with harmless noise-fitting) to achieve generalization error close to the bound on interpolative solutions.