 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Predict DB
Paper and Code
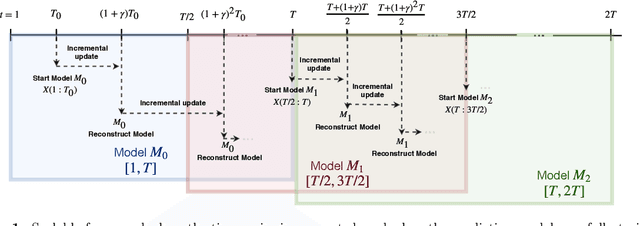
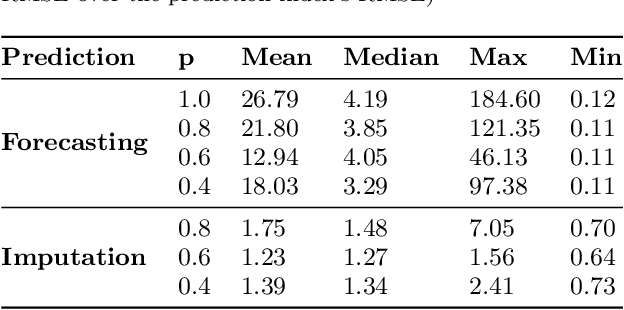


In this work, we are motivated to make predictive functionalities native to database systems with focus on time series data. We propose a system architecture, Time Series Predict DB, that enables predictive query in any existing time series database by building an additional "prediction index" for time series data. To be effective, such an index needs to be built incrementally while keeping up with database throughput, able to scale with volume of data, provide accurate predictions for heterogeneous data, and allow for "predictive" querying with latency comparable to the traditional database queries. Building upon a recently developed model agnostic time series algorithm by making it incremental and scalable, we build such a system on top of PostgreSQL. Using extensive experimentation, we show that our incremental prediction index updates faster than PostgreSQL ($1\mu s$ per data for prediction index vs $4\mu s$ per data for PostgreSQL) and thus not affecting the throughput of the database. Across a variety of time series data, we find? that our incremental, model agnostic algorithm provides better accuracy compared to the best state-of-art time series libraries (median improvement in range 3.29 to 4.19x over Prophet of Facebook, 1.27 to 1.48x over AMELIA in R). The latency of predictive queries with respect to SELECT queries (0.5ms) is < 1.9x (0.8ms) for imputation and < 7.6x (3ms) for forecasting across machine platforms. As a by-product, we find that the incremental, scalable variant we propose improves the accuracy of the batch prediction algorithm which may be of interest in its own right.