 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTucker Tensor Layer in Fully Connected Neural Networks
Paper and Code
Mar 14, 2019
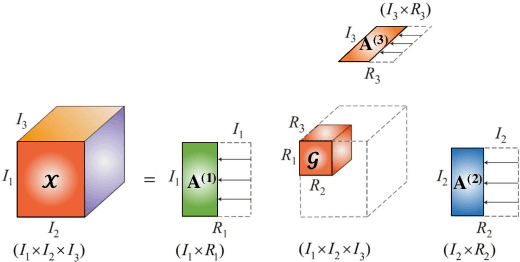

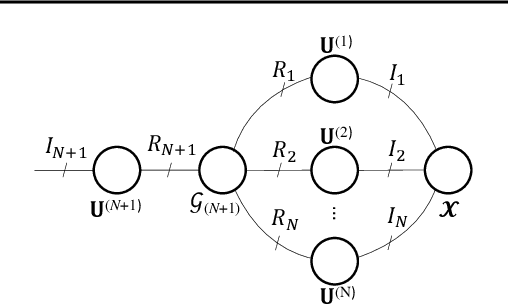
We introduce the Tucker Tensor Layer (TTL), an alternative to the dense weight-matrices of the fully connected layers of feed-forward neural networks (NNs), to answer the long standing quest to compress NNs and improve their interpretability. This is achieved by treating these weight-matrices as the unfolding of a higher order weight-tensor. This enables us to introduce a framework for exploiting the multi-way nature of the weight-tensor in order to efficiently reduce the number of parameters, by virtue of the compression properties of tensor decompositions. The Tucker Decomposition (TKD) is employed to decompose the weight-tensor into a core tensor and factor matrices. We re-derive back-propagation within this framework, by extending the notion of matrix derivatives to tensors. In this way, the physical interpretability of the TKD is exploited to gain insights into training, through the process of computing gradients with respect to each factor matrix. The proposed framework is validated on synthetic data and on the Fashion-MNIST dataset, emphasizing the relative importance of various data features in training, hence mitigating the "black-box" issue inherent to NNs. Experiments on both MNIST and Fashion-MNIST illustrate the compression properties of the TTL, achieving a 66.63 fold compression whilst maintaining comparable performance to the uncompressed NN.