 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models for Low-Rank Video Representation and Reconstruction
Paper and Code
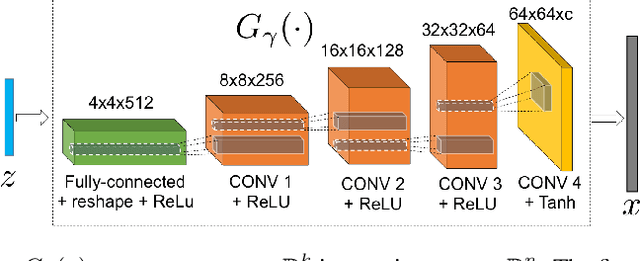
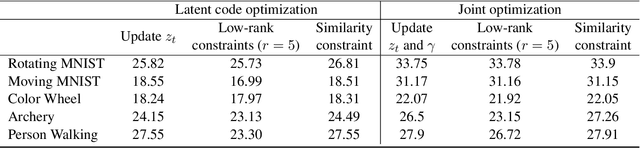
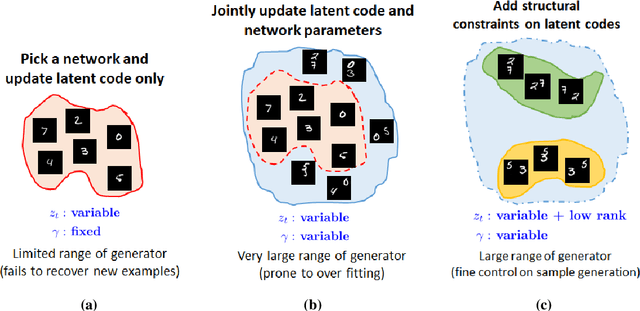
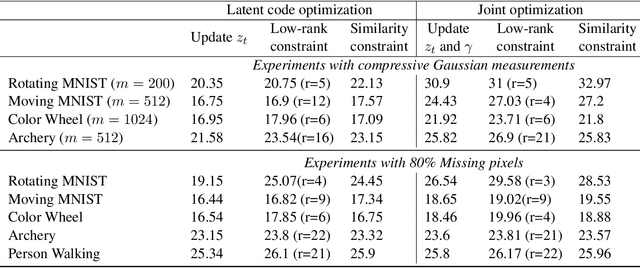
Finding compact representation of videos is an essential component in almost every problem related to video processing or understanding. In this paper, we propose a generative model to learn compact latent codes that can efficiently represent and reconstruct a video sequence from its missing or under-sampled measurements. We use a generative network that is trained to map a compact code into an image. We first demonstrate that if a video sequence belongs to the range of the pretrained generative network, then we can recover it by estimating the underlying compact latent codes. Then we demonstrate that even if the video sequence does not belong to the range of a pretrained network, we can still recover the true video sequence by jointly updating the latent codes and the weights of the generative network. To avoid overfitting in our model, we regularize the recovery problem by imposing low-rank and similarity constraints on the latent codes of the neighboring frames in the video sequence. We use our methods to recover a variety of videos from compressive measurements at different compression rates. We also demonstrate that we can generate missing frames in a video sequence by interpolating the latent codes of the observed frames in the low-dimensional space.