Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Neural-based Dialog Act Classification on Automatically Generated Transcriptions
Paper and Code
Feb 28, 2019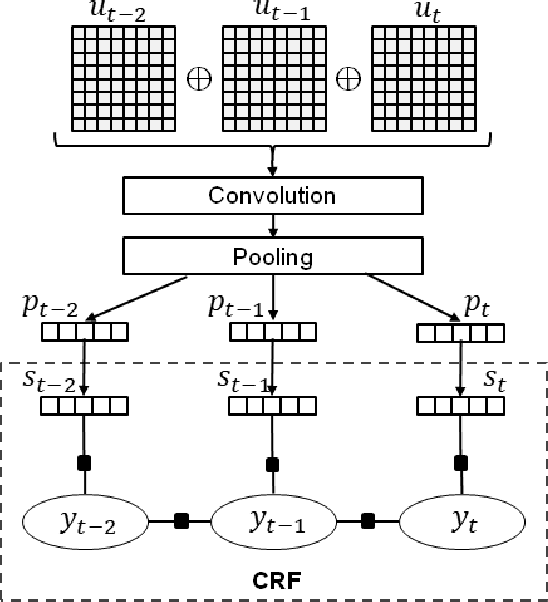
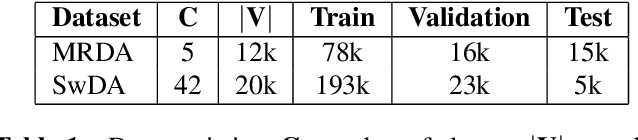
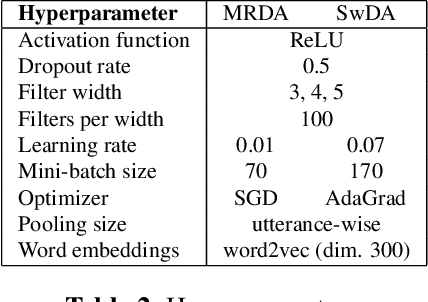
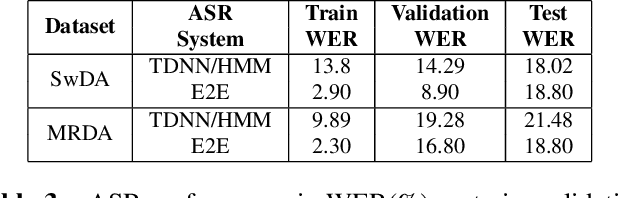
This paper presents our latest investigations on dialog act (DA) classification on automatically generated transcriptions. We propose a novel approach that combines convolutional neural networks (CNNs) and conditional random fields (CRFs) for context modeling in DA classification. We explore the impact of transcriptions generated from different automatic speech recognition systems such as hybrid TDNN/HMM and End-to-End systems on the final performance. Experimental results on two benchmark datasets (MRDA and SwDA) show that the combination CNN and CRF improves consistently the accuracy. Furthermore, they show that although the word error rates are comparable, End-to-End ASR system seems to be more suitable for DA classification.
* 5 pages, 1 figure, ICASSP 2019, dialog act classification, automatic
speech recognition
View paper on