 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Tree-LSTM: Structure-aware Attentional Document Encoders
Paper and Code
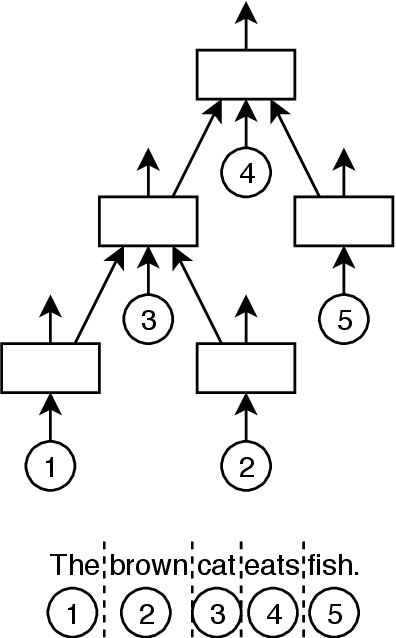

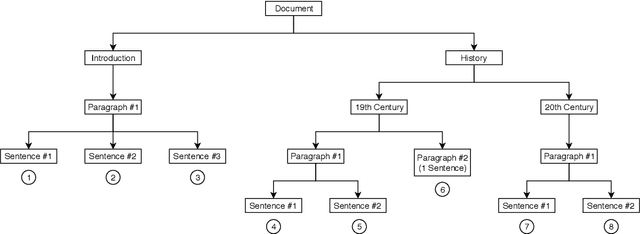
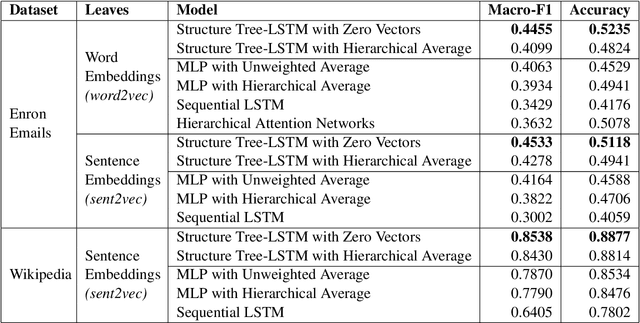
We propose a method to create document representations that reflect their internal structure. We modify Tree-LSTMs to hierarchically merge basic elements like words and sentences into blocks of increasing complexity. Our Structure Tree-LSTM implements a hierarchical attention mechanism over individual components and combinations thereof. We thus emphasize the usefulness of Tree-LSTMs for texts larger than a sentence. We show that structure-aware encoders can be used to improve the performance of document classification. We demonstrate that our method is resilient to changes to the basic building blocks, as it performs well with both sentence and word embeddings. The Structure Tree-LSTM outperforms all the baselines on two datasets when structural clues like sections are available, but also in the presence of mere paragraphs. On a third dataset from the medical domain, our model achieves competitive performance with the state of the art. This result shows the Structure Tree-LSTM can leverage dependency relations other than text structure, such as a set of reports on the same patient.