 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn entropic feature selection method in perspective of Turing formula
Paper and Code
Feb 19, 2019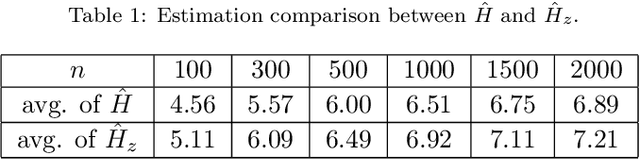
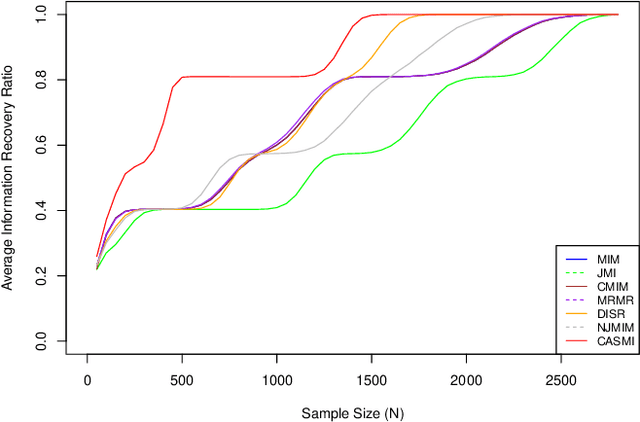
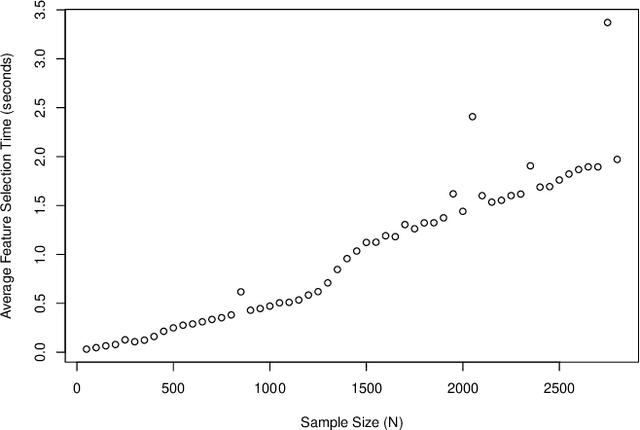
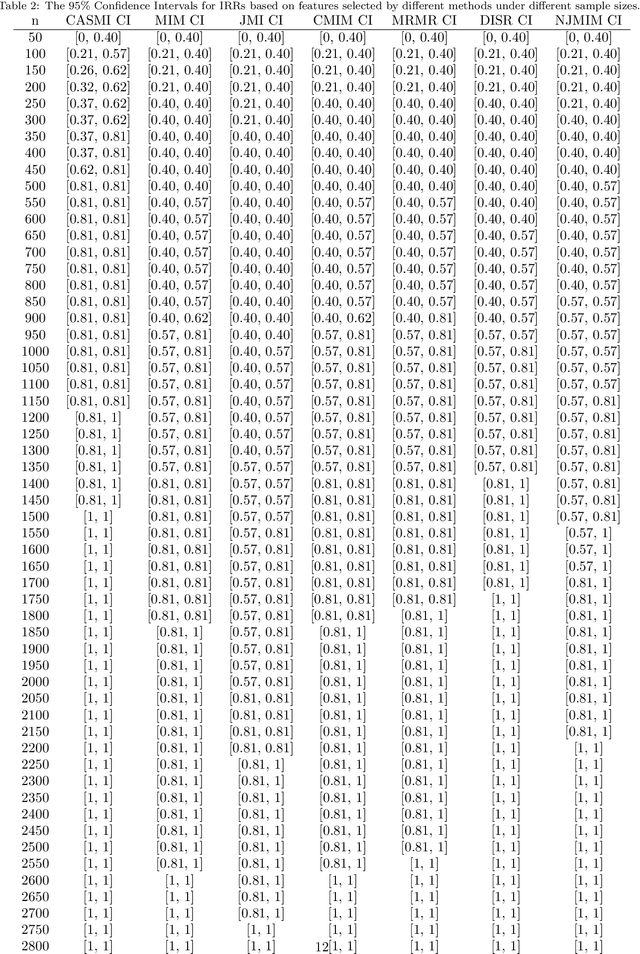
Health data are generally complex in type and small in sample size. Such domain-specific challenges make it difficult to capture information reliably and contribute further to the issue of generalization. To assist the analytics of healthcare datasets, we develop a feature selection method based on the concept of Coverage Adjusted Standardized Mutual Information (CASMI). The main advantages of the proposed method are: 1) it selects features more efficiently with the help of an improved entropy estimator, particularly when the sample size is small, and 2) it automatically learns the number of features to be selected based on the information from sample data. Additionally, the proposed method handles feature redundancy from the perspective of joint-distribution. The proposed method focuses on non-ordinal data, while it works with numerical data with an appropriate binning method. A simulation study comparing the proposed method to six widely cited feature selection methods shows that the proposed method performs better when measured by the Information Recovery Ratio, particularly when the sample size is small.