 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform convergence may be unable to explain generalization in deep learning
Paper and Code
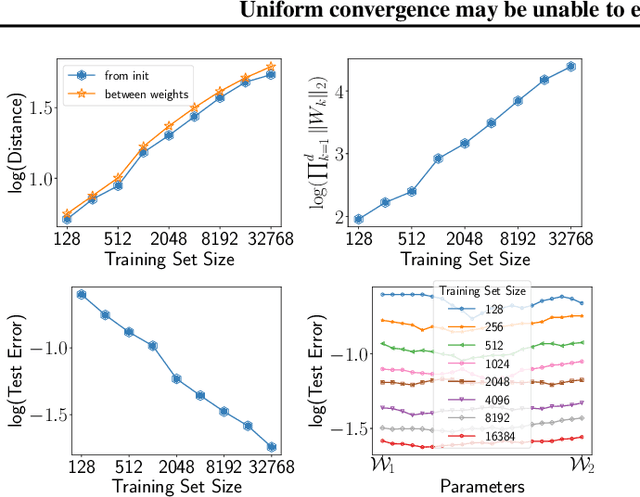
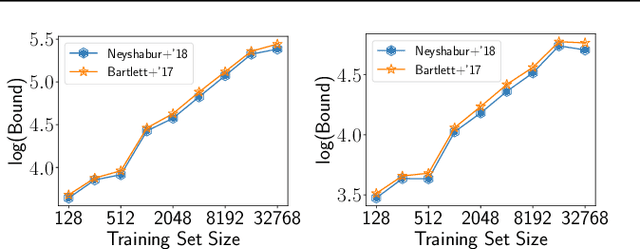
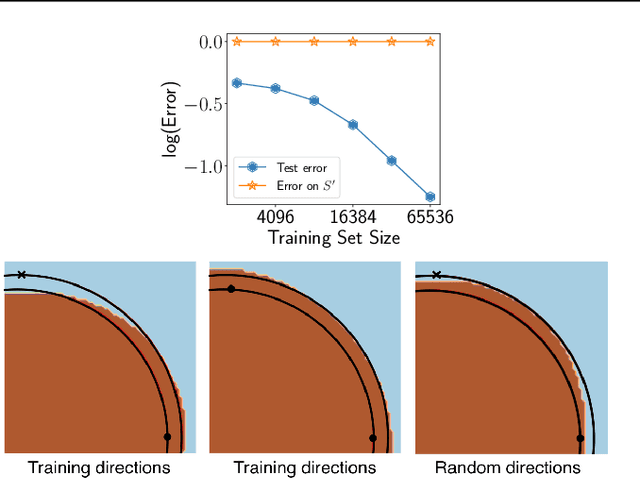
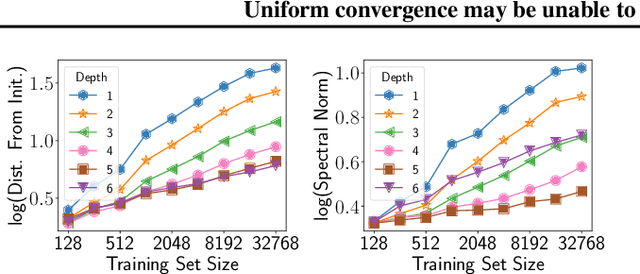
We cast doubt on the power of uniform convergence-based generalization bounds to provide a complete picture of why overparameterized deep networks generalize well. While it is well-known that many existing bounds are numerically large, through a variety of experiments, we first bring to light another crucial and more concerning aspect of these bounds: in practice, these bounds can {\em increase} with the dataset size. Guided by our observations, we then present examples of overparameterized linear classifiers and neural networks trained by stochastic gradient descent (SGD) where uniform convergence provably cannot `explain generalization,' even if we take into account implicit regularization {\em to the fullest extent possible}. More precisely, even if we consider only the set of classifiers output by SGD that have test errors less than some small $\epsilon$, applying (two-sided) uniform convergence on this set of classifiers yields a generalization guarantee that is larger than $1-\epsilon$ and is therefore nearly vacuous.