 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Segmenting Everything That Moves
Paper and Code
Feb 11, 2019
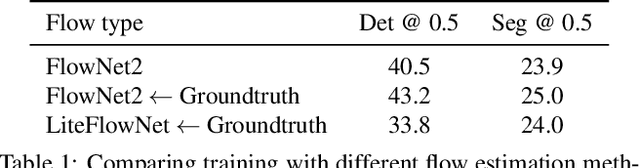


Video analysis is the task of perceiving the world as it changes. Often, though, most of the world doesn't change all that much: it's boring. For many applications such as action detection or robotic interaction, segmenting all moving objects is a crucial first step. While this problem has been well-studied in the field of spatiotemporal segmentation, virtually none of the prior works use learning-based approaches, despite significant advances in single-frame instance segmentation. We propose the first deep-learning based approach for video instance segmentation. Our two-stream models' architecture is based on Mask R-CNN, but additionally takes optical flow as input to identify moving objects. It then combines the motion and appearance cues to correct motion estimation mistakes and capture the full extent of objects. We show state-of-the-art results on the Freiburg Berkeley Motion Segmentation dataset by a wide margin. One potential worry with learning-based methods is that they might overfit to the particular type of objects that they have been trained on. While current recognition systems tend to be limited to a "closed world" of N objects on which they are trained, our model seems to segment almost anything that moves.