 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Optimization Framework for Task Sequencing in Curriculum Learning
Paper and Code
Mar 11, 2019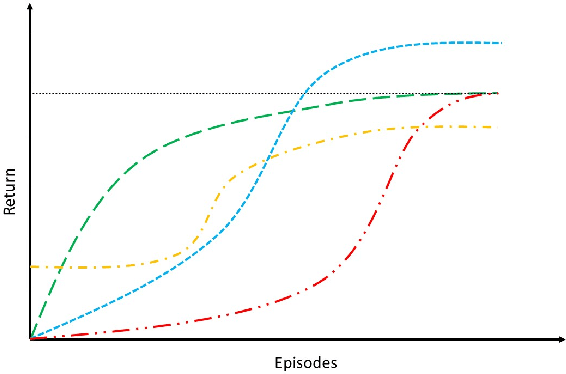
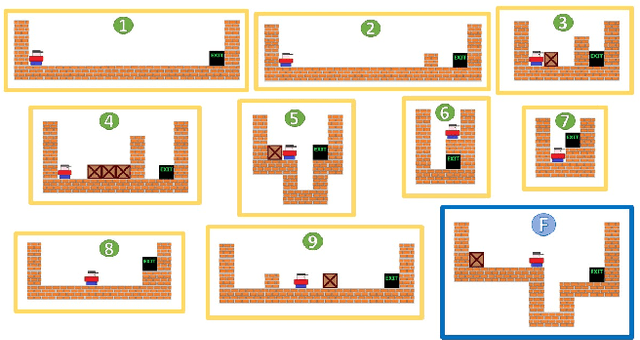

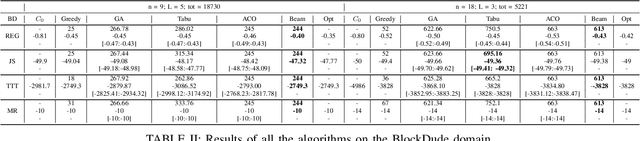
Curriculum learning in reinforcement learning is used to shape exploration by presenting the agent with increasingly complex tasks. The idea of curriculum learning has been largely applied in both animal training and pedagogy. In reinforcement learning, all previous task sequencing methods have shaped exploration with the objective of reducing the time to reach a given performance level. We propose novel uses of curriculum learning, which arise from choosing different objective functions. Furthermore, we define a general optimization framework for task sequencing and evaluate the performance of popular metaheuristic search methods on several tasks. We show that curriculum learning can be successfully used to: improve the initial performance, take fewer suboptimal actions during exploration, and discover better policies.