 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Label Distillation: Learning Input-Efficient Deep Neural Networks
Paper and Code
Jan 26, 2019
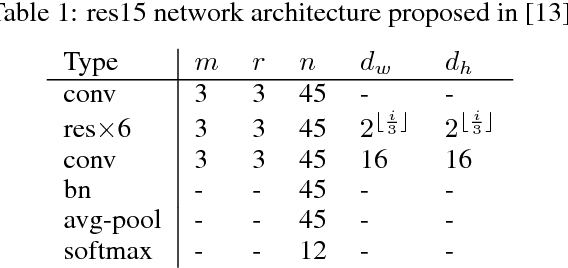
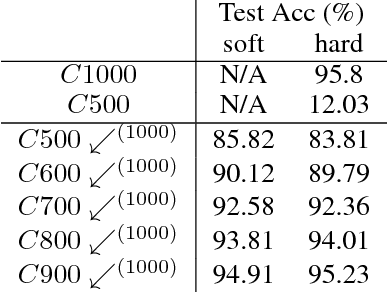
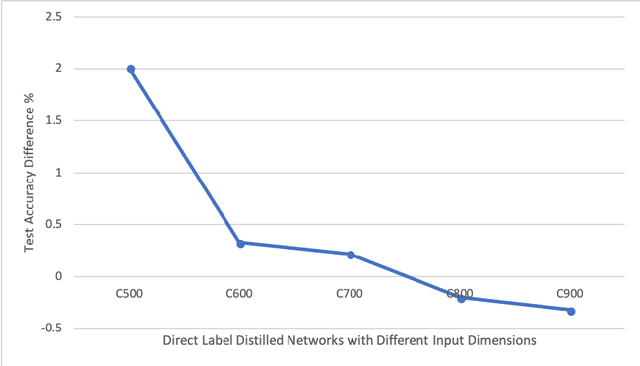
Much of the focus in the area of knowledge distillation has been on distilling knowledge from a larger teacher network to a smaller student network. However, there has been little research on how the concept of distillation can be leveraged to distill the knowledge encapsulated in the training data itself into a reduced form. In this study, we explore the concept of progressive label distillation, where we leverage a series of teacher-student network pairs to progressively generate distilled training data for learning deep neural networks with greatly reduced input dimensions. To investigate the efficacy of the proposed progressive label distillation approach, we experimented with learning a deep limited vocabulary speech recognition network based on generated 500ms input utterances distilled progressively from 1000ms source training data, and demonstrated a significant increase in test accuracy of almost 78% compared to direct learning.