 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Rules for Fooling Deep Neural Networks based Text Classification
Paper and Code
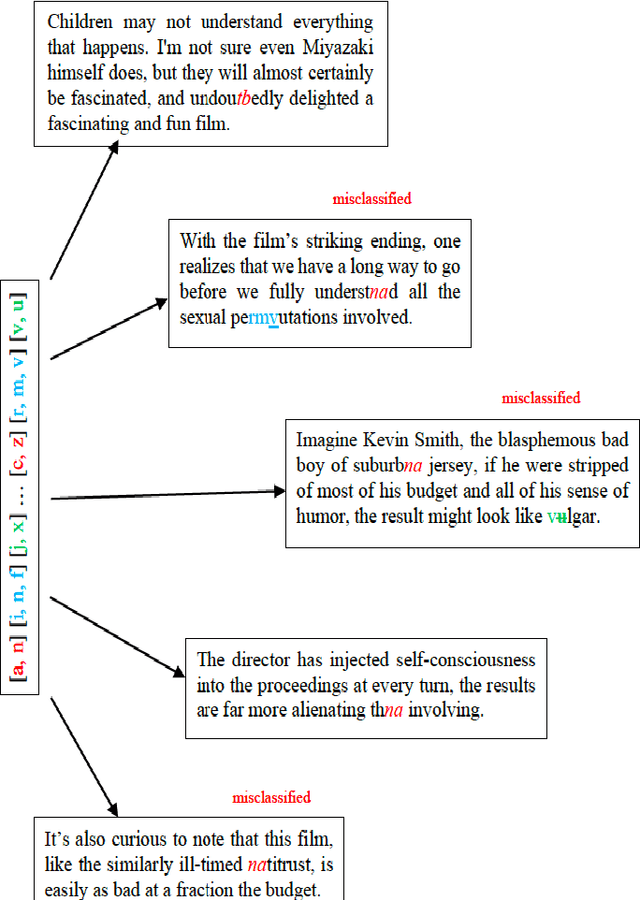
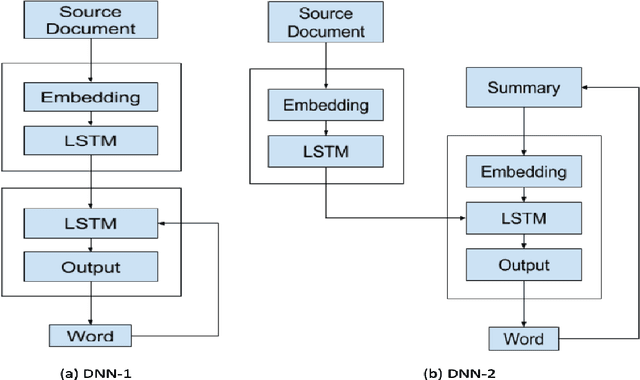
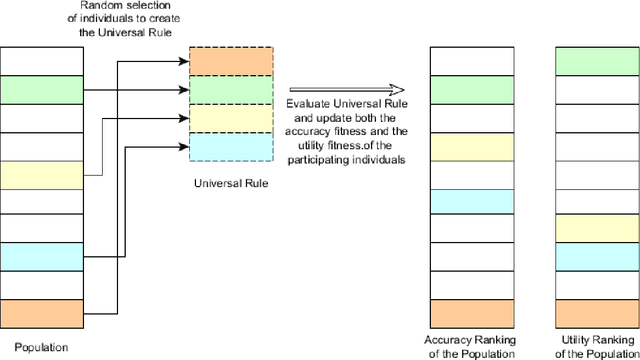
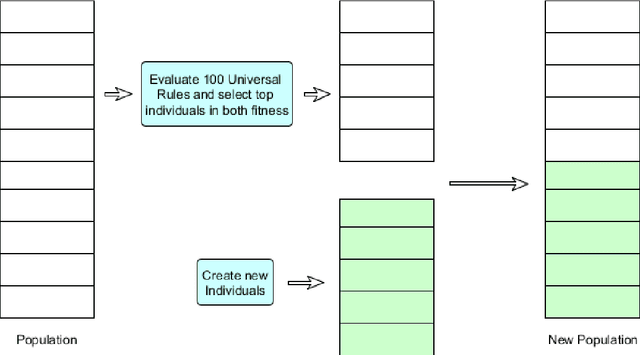
Recently, deep learning based natural language processing techniques are being extensively used to deal with spam mail, censorship evaluation in social networks, among others. However, there is only a couple of works evaluating the vulnerabilities of such deep neural networks. Here, we go beyond attacks to investigate, for the first time, universal rules, i.e., rules that are sample agnostic and therefore could turn any text sample in an adversarial one. In fact, the universal rules do not use any information from the method itself (no information from the method, gradient information or training dataset information is used), making them black-box universal attacks. In other words, the universal rules are sample and method agnostic. By proposing a coevolutionary optimization algorithm we show that it is possible to create universal rules that can automatically craft imperceptible adversarial samples (only less than five perturbations which are close to misspelling are inserted in the text sample). A comparison with a random search algorithm further justifies the strength of the method. Thus, universal rules for fooling networks are here shown to exist. Hopefully, the results from this work will impact the development of yet more sample and model agnostic attacks as well as their defenses, culminating in perhaps a new age for artificial intelligence.