 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-in-the-Loop Adversarial Examples
Paper and Code
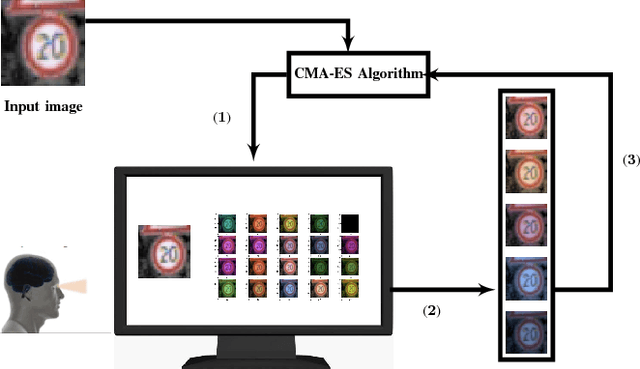



We present a scalable, black box, perception-in-the-loop technique to find adversarial examples for deep neural network classifiers. Black box means that our procedure only has input-output access to the classifier, and not to the internal structure, parameters, or intermediate confidence values. Perception-in-the-loop means that the notion of proximity between inputs can be directly queried from human participants rather than an arbitrarily chosen metric. Our technique is based on covariance matrix adaptation evolution strategy (CMA-ES), a black box optimization approach. CMA-ES explores the search space iteratively in a black box manner, by generating populations of candidates according to a distribution, choosing the best candidates according to a cost function, and updating the posterior distribution to favor the best candidates. We run CMA-ES using human participants to provide the fitness function, using the insight that the choice of best candidates in CMA-ES can be naturally modeled as a perception task: pick the top $k$ inputs perceptually closest to a fixed input. We empirically demonstrate that finding adversarial examples is feasible using small populations and few iterations. We compare the performance of CMA-ES on the MNIST benchmark with other black-box approaches using $L_p$ norms as a cost function, and show that it performs favorably both in terms of success in finding adversarial examples and in minimizing the distance between the original and the adversarial input. In experiments on the MNIST, CIFAR10, and GTSRB benchmarks, we demonstrate that CMA-ES can find perceptually similar adversarial inputs with a small number of iterations and small population sizes when using perception-in-the-loop. Finally, we show that networks trained specifically to be robust against $L_\infty$ norm can still be susceptible to perceptually similar adversarial examples.